NLP Preprocessing, RNNs
자연어처리를 위한 데이터 전처리
1.NLP 전처리

1-1.Raw Corpus
- NLP task에서 사용되는 대규모 텍스트 데이터 집합을 Corpus라고 한다.
- 웹, 문서, 깃허브 리포지토리 등 다양한 출처에서 수집된 텍스트로 구성되기 때문에 굉장히 규모가 크다.
- 다만, 어떠한 가공도 적용되지 않았기 때문에 굉장히 노이즈가 많은 상태이다.
1-2.Quality Filtering
- 품질이 낮은 데이터를 수정하거나 제거하는 단계.
- 목적에 맞지 않은 언어가 아닌 텍스트를 제거하며 지나치게 길이가 짧거나 의미 없는 데이터를 제거한다.
- 오타, 깨진 글자, HTML 태그, 특수문자, 이모티콘 등이 대표적 예시.
1-3.De-Duplication
- 중복되는 문장이나 문서를 제거한다.
- 데이터셋에 중복되는 데이터가 많다면 학습시 모델은 해당 샘플들에 과적합 + 편향적인 모델이 만들어질 가능성이 높다.
- 컴퓨팅 자원을 낭비하는 형태가 된다.(어차피 사용해야할 자원이라면 더 다양한 샘플들을 적재하는 것이 바람직함.)
1-4.Privacy Reduction
- 개인정보를 익명처리하거나 제거한다.
- 학습 데이터에 이름, 주소, 전화번호 등 민감한 정보가 포함될 수 있는데, 이를 자동으로 탐지하여 제거하거나 익명처리한다.
1-5.Tokenization
정의
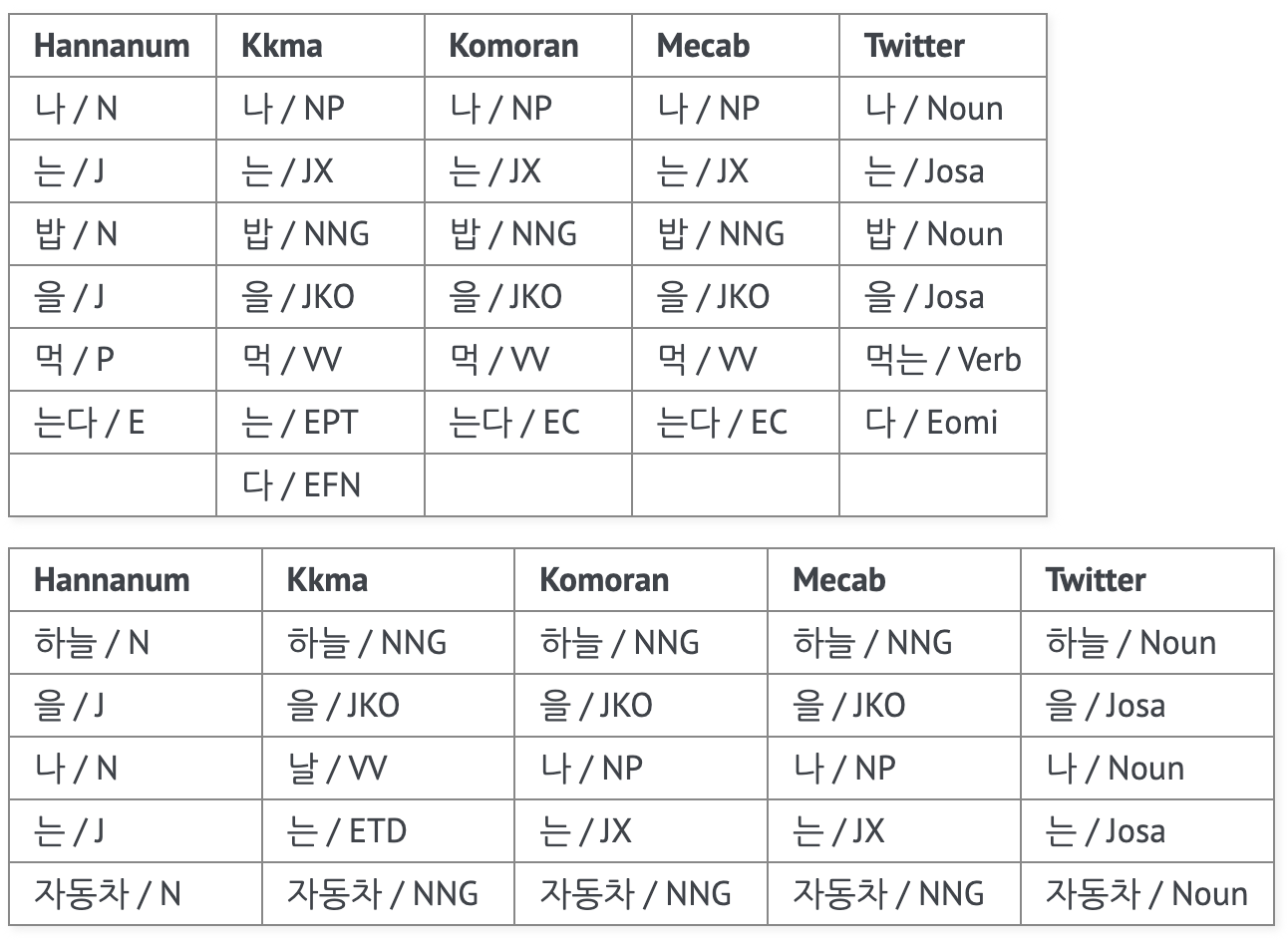
토큰화는 모델이 이해할 수 있는 형태로 데이터를 변환하는 단계로, 데이터를 토큰 단위로 분절하는 작업이다. 쉽게 말해 입력으로 들어온 문장을 토큰 단위로 나눠주는 작업을 말한다.
- 토크나이저를 통해 입력된 문장을 토큰 단위로 쪼개고, 각각의 토큰들을 사전(Vocabulary)에 매칭시켜 정수형 id로 변환한다.
- 어절, 음절, 형태소, 단어, 문장 등 분절을 위한 기준은 다양한데 어떤 것을 기준으로 하는가에 따라 토큰화 결과가 달라지게 된다.
- 결과적으로 입력값이 달라지며 학습도 다르게 되는 것이니 성능이 달라질 수 있다.
토큰화 시 고려해야할 사항들은 다음과 같다.
- 구두점이나 특수 문자를 제외한다.(24/08/23, $100,000 등)
- 줄임말(we’re -> we are)이나 하나의 단어지만 띄어쓰기가 존재 (rock n roll -> rock and roll)
- 문장을 기준으로 할 때는 단순히 마침표를 기준으로 자를 수 없음에 주의해야한다.
- 한국어 특성상 다양한 조사가 붙을 수 있고, 그에 따라 의미가 달라지기 때문에 형태소 단위의 토큰화가 필요하다.
- 또한 한국어는 영어보다 띄어쓰기가 불규칙적이기 때문에 이 부분도 주의해야한다.
특성1.Subword Tokenizer
Corpus내 문장들을 순회하면서 각각의 문장을 띄어쓰기 기준으로 분절한다면 이 과정에서 고유한 단어들이 구해지게 되고 이들을 모은 것이 단어사전(vocabulary)이다.
여기서 주의할 점은 다음과 같다.
- 다음 단어를 예측하는 language model이나 기계변역 작업을 하는 경우 모델의 출력은 vocab의 크기가 곧 차원에 해당한다.
- 즉, 너무 많은 단어를 사전에 담게 되면 출력 벡터가 굉장히 고차원이 되므로 학습이 어려워진다.
- 뿐만 아니라 띄어쓰기나 word2vec처럼 단순히 단어를 벡터로 변환하게 된다면 vocab에 포함되지 않는 단어가 있을 때 UNK 토큰으로 처리해야한다.
즉, 토크나이저를 만들 때 vocab을 적절한 크기로 구축하는 것과 vocab에 포함되지 않은 단어에 대한 처리(Out Of Vocab)를 해결하는 것이 중요하다.
이러한 문제들을 해결하기 위해 Subword Tokenizer라는 것이 개발되었다.
- 이는 하나의 단어를 하위 단위 단어로 분리해서 토큰화 및 vocab을 구축하게 한다.
- 예를 들어 CrossEntropy라는 단어가 있다면, ‘Cross’, ‘Entropy’로 분할한다.
- 이렇게 하면 OOV 문제와 희귀 단어, 신조어 같은 문제들을 완화할 수 있게 된다.
- 대표적인 Subword Tokenizer는 Byte Pair Encoding, WordPiece 방식이 있다.
BPE
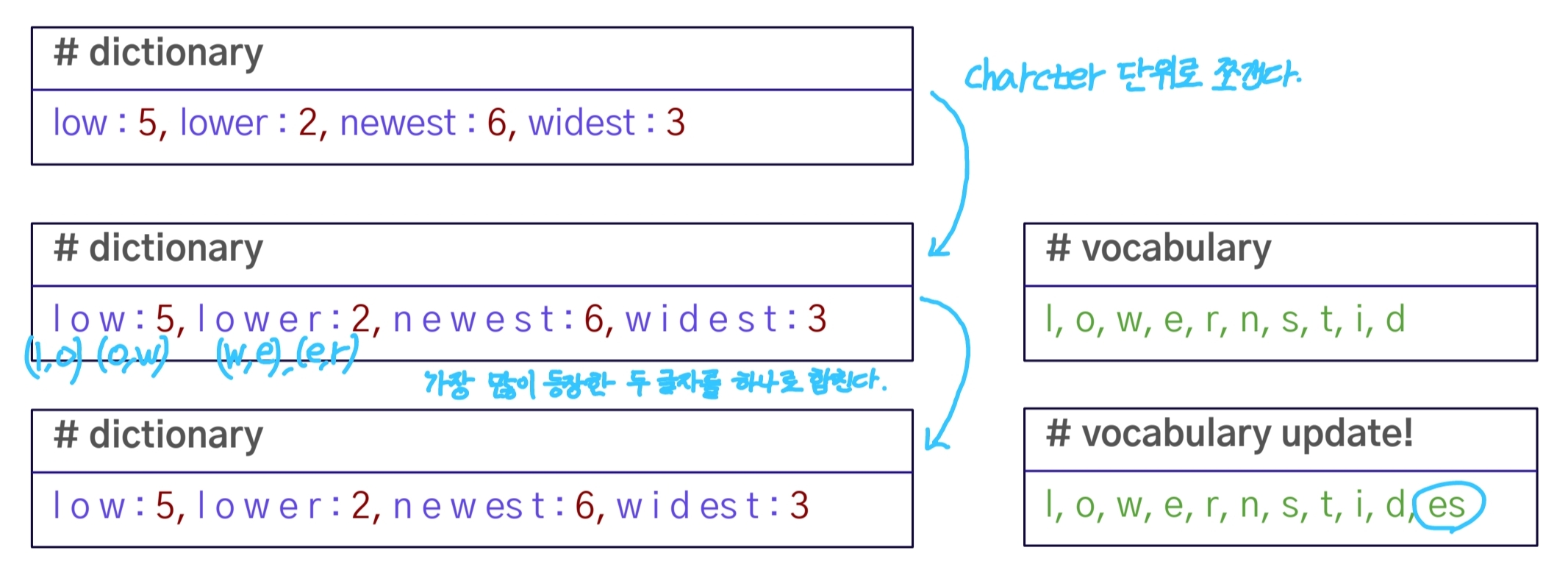
연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합한다. 즉, 글자 단위에서 점진적으로 단어 집합을 만들어내는 Bottom-up 방식이다.
- “low”, “lower”, “newest”, “widest”라는 단어들이 주어져 있으며 각 단어들의 빈도수가 명시되어 있다.
- 각각의 단어들을 알파벳 단위로 분할하고 vocab에 추가한다. -> “l”, “o”, “w”, “e”, “r”, “n”, “s”, “t”, “i”, “d” 같은 개별 문자가 vocabulary에 포함.
- 빈도수가 가장 높은 문자 쌍을 병합. ‘lo’, ‘ow’와 같은 쌍이 병합되어 하나의 토큰으로 취급.
즉, 각 병합 단계마다 자주 등장하는 쌍이 병합됨에 따라 vocabulary에 새로운 서브워드들이 추가하는 방식으로 진행된다.
Word Piece

WordPiece는 빈도 기반보다는 확률적 언어 모델을 사용해 서브워드를 병합하고 선택하는 방식이다.
- BPE는 문자쌍의 빈도수에 따라 병합하지만, Wordpiece는 Maximum Likelihood를 기반으로 서브워드를 병합한다.
- 특정 문자 쌍이 문맥 내에서 등장할 확률을 계산하고, 이 확률을 최대화하는 서브워드 쌍을 병합한다.
- 즉, 두 서브워드를 병합했을 때 그 서브워드의 새 확률 분포가 더 자연스럽고 적합한지 확인한 후 병합하는 방식.
- 이후 분할 시점에서는 텍스트를 완전한 단어로 변환하기보다는, 해당 단어를 서브워드로 나누게 된다.
- 예를 들어 “unhappiness”라는 단어는 사전에 없을 수 있지만, “un”, “happiness”로 나눌 수 있고, 추가로 “happi”, “ness”와 같은 서브워드로 더 세분화할 수도 있다.
특성2. Pretrained Language Model
Huggingface에서 사전학습된 Tokenizer를 사용할 수 있는 방법 등을 다룰 때 주의할점.
- huggingface의 경우 Pretrained Language Model(PLM)과 Tokenizer가 세트로 사용되어야만 한다.
- 만약 토크나이저를 별도로 구축하는 경우 모델의 출력과 토크나이저가 불일치하기 때문에 부적절한 결과가 만들어지게 된다.
- 보통 Pretrain 단계부터(즉, scratch부터) 시작하려는 경우 대규모 corpus를 이용해 토크나이저를 새로 정의하고 사전학습을 수행한다.
정리하면 PLM을 사용하든 scratch부터 하든 어떤 토크나이저가 좋은지 판단하는 것이 핵심이다. 예를 들어
원문 : “안녕하세요, 오늘은 날씨가 좋네요.” 를 서로 다른 두 개의 토크나이저로 분절한 결과가 다음과 같다면 어떤 토크나이저가 더 좋은 것일까??
- Tokenizer 1 ) → **[‘▁안녕’, ‘하세요’, ‘,’, ‘▁오늘은’, ‘▁날’, ‘씨가’, ‘▁좋네요’, ‘.’]
- Tokenizer 2 ) → **[‘ㅇ’, ‘ㅏ’, ‘ㄴ’, ‘ㄴ’, ‘ㅕ’, ‘ㅇ’, ‘ㅎ’, ‘ㅏ’, ‘ㅅ’, ‘ㅔ’, ‘ㅇ’, ‘ㅛ’, …..]
일반적으로 임의의 문장을 나누었을때, 적은 토큰 개수로 나누는 1번 토크나이저를 좋은 토크나이저라고 한다.
- 적은 수로 토큰화를 하게 되면 학습시 모델에 입력되는 토큰의 수가 줄어들어 학습, 추론에 있어 효율적이다.
- LM은 결국 vocab 차원의 벡터의 원소 중 가장 확률이 높은 하나의 토큰이 선택되기 때문에 토크나이저가 적절한 토큰들로 분절하는 경우 vocab의 크기가 적절해진다.
- 각각의 토큰이 원본 데이터가 갖는 의미를 온전히 담을 수 있게 된다.
- 최근에는 Byte-Pair Encoding(BPE), SentencePiece, WordPiece와 같이 subword로 토큰화 하는 방식을 채택함으로써 Vocab에 없는 단어도 처리할 수 있게되며 vocab의 크기가 커지는 것을 방지할 수 있다.
1-6.Cleaning
1-1 ~ 1-4에서 어느정도 정제를 수행하겠지만, tokenization을 한 후에도 정제작업이 필요하다.
- 특수문자 같은 의미없는 글자들 뿐만 아니라 분석하려는 목적에 맞지 않는 불필요한 단어들도 노이즈에 해당하므로 제거한다.
- 불용어(StopWord), 특수문자 제거, 대소문자 통합, 중복되는 글자 제거, 다중 공백 통일 등등
- 불용어는 corpus 내에 빈번하게 등장하더라도 분석에 있어 의미가 없는 단어를 말한다.
- 전처리 과정에서 어떤 문자들을 불용어로 취급할 것인지 사전 정의하는 과정이 필요하다.
1-7.Normalization

텍스트 데이터의 정규화는 어간추출(Stemming)과 표재어추출(Lemmatizing)이 있다.
- 어간추출은 어형이 변형된 단어로부터 접사 등을 제거해 어간을 추출하는 것이다.(allowance -> allow, electrical -> elcetric)
- 표제어추출은 품사 정보가 보존된 형태의 기본형으로 변환한다. 즉, 형태소 분석으로 얻은 결과에서 명사면 명사, 동사면 동사임을 유지하면서 원형을 추출하는 방식.(cats -> cat, dies -> die)
이와 같은 정규화 방식은 예외적인 것들을 최소화함으로써 통일성을 높혀 연산 효율성을 높이는 효과가 있다.
2.RNNs
2-1.RNN
구조
자연어처리에서 다루는 텍스트 데이터는 단어들의 배열 순서가 반영되어 있는 Seqeunce Data이다. 이전에 공부했던 MLP, CNN 같은 모델들은 순서를 반영하여 학습하는 방식이 아니기 때문에 더 적합한 구조가 필요했고, 이를 위해 Recurrent Nerual Network이 개발되었다.
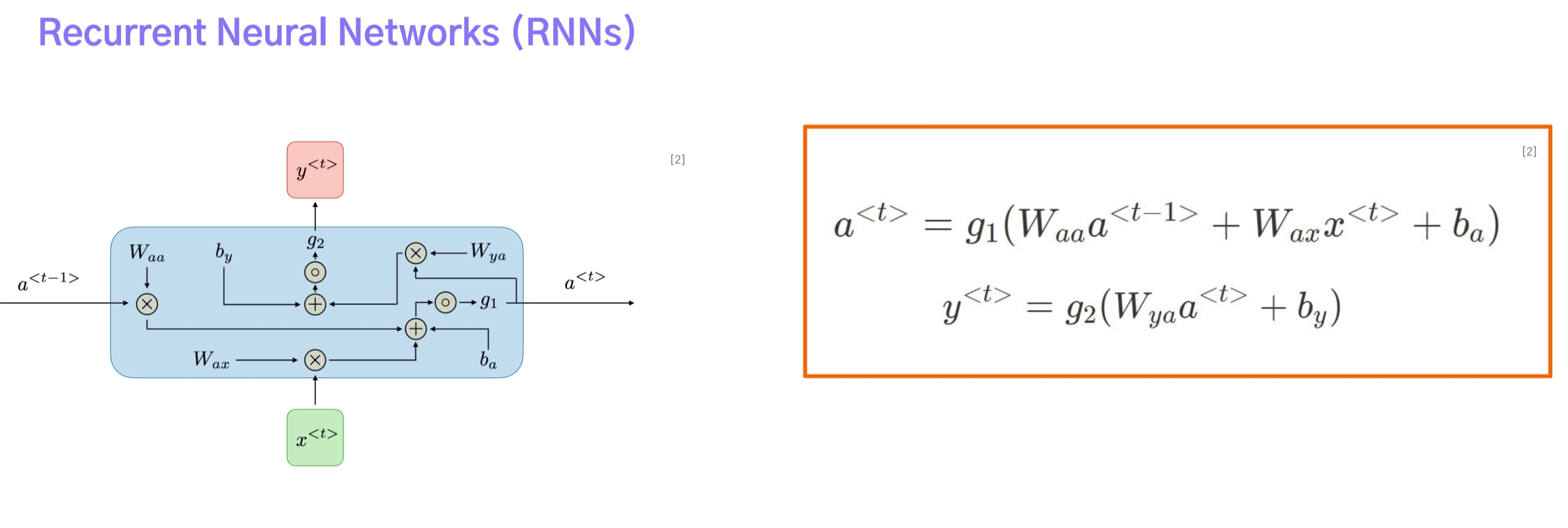
- $ a_{t-1}, a_{t} $는 RNN 계열에서 등장하는 hidden state이며 첫번째 단계부터 현재 단계 t까지의 정보들을 저장하는 메모리 역할을 한다.
- 이전 시간 단계의 hidden state를 현재 시간 단계로 전달하는 방식으로 학습이 진행된다.
- $ a_{t-1}, x_{t}, a_{t} $ 각각에는 서로 다른 가중치 $ W_{aa}, W_{ax}, W_{ya} $가 적용되며 하나의 데이터(또는 batch)를 첫번째 단어부터 마지막 글자를 볼 때까지 공유되는 weight sharing이다.
- 참고로 $ y_t $는 t번째 단계에서 모델의 출력을 구하기 위할 때 사용된다.
- 시간순서에 따라 학습이 진행되기 때문에 역전파도 시간의 역순으로 수행된다.(Backpropagation through time, BPTT)
RNN은 시간 t마다 hidden state를 구하고 이를 출력층에 입력해 출력값을 얻을 수 있다. 따라서 위 그림에서 볼 수 있듯 다양한 RNN 구조들을 볼 수 있다.
- one-to-one : image classification
- one-to-many : image captioning
- many-to-one : text classification
- many-to-many : machine translation, text generation
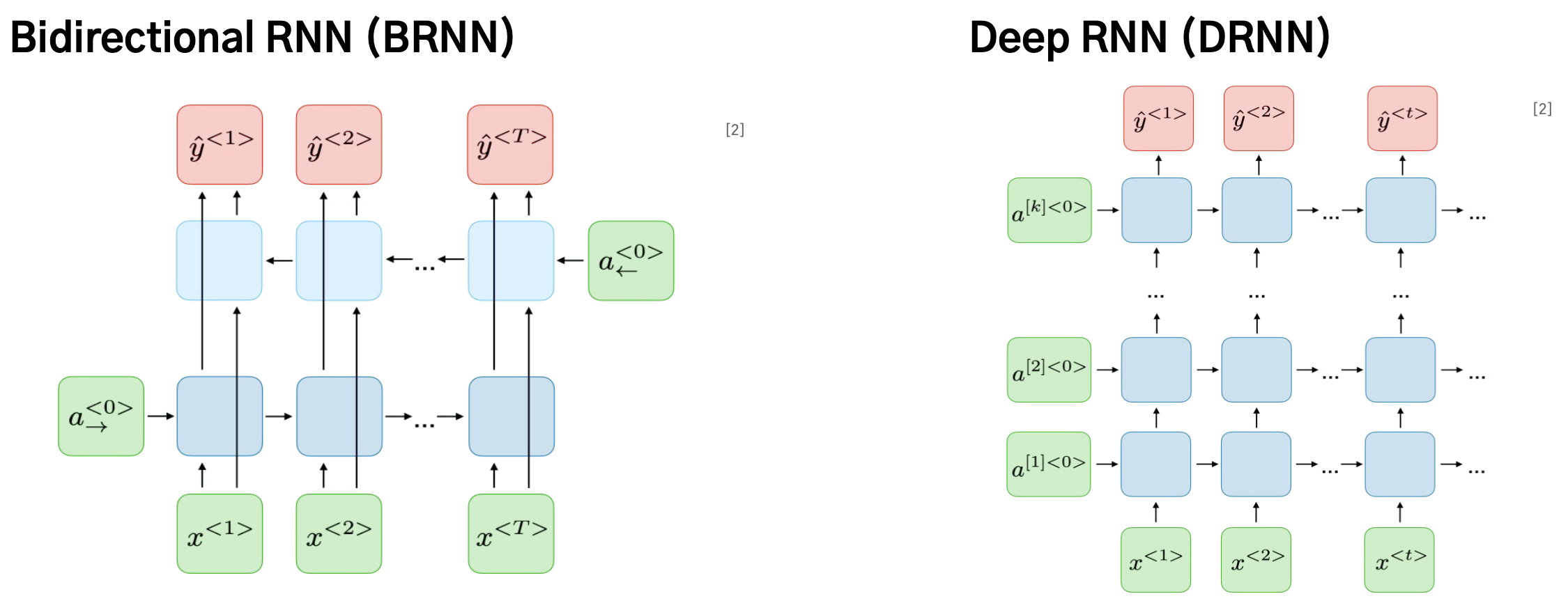
- 마지막에서부터 첫번째로 한 번 더 순회하는 방식을 Bidirectional RNN
- 각 시간 t마다 여러 개의 층을 통과하게 되는 경우 Deep RNN
장단점
RNN의 장점
- 모든 길이의 시퀀스 데이터를 입력으로 처리할 수 있다.(즉, 순서를 반영할 수 있다.)
- 가중치를 공유하기 때문에 입력 시퀀스가 길어도 모델의 크기가 증가하지 않는다.
- 참고로 가중치 공유는 파라미터 수를 줄일 수 있다는 점도 있지만, 동일한 가중치로 데이터의 시작부터 끝까지 보게 되므로 특정 패턴이 어디에서 발생하든 학습할 수 있게 만든다.
RNN의 단점
- 시간 t마다 hidden state를 계산해야만 다음 스텝에서의 hidden state를 구할 수 있기 때문에 병렬처리가 불가능하다.(속도가 느리다.)
- 입력 또는 출력 시퀀스가 길어지는 경우 오래전(초반부 입력) 정보가 희미해져 반영이 어려워진다. 즉, 전체 문맥을 반영하는게 어렵다.
- 현재의 hidden state를 구하는데에 과거정보만을 반영할 뿐, 미래정보를 반영할 수 없다.
Vanishing, Exploding Gradient
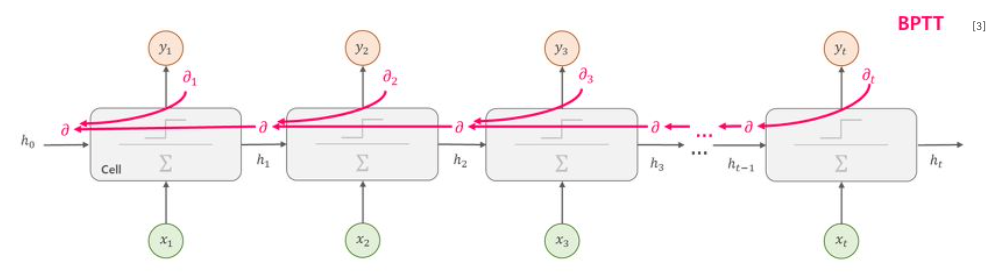
앞서 RNN에서 수행되는 수식을 보면 tanh가 활성화 함수로 사용되고 있음을 확인할 수 있다. 역전파에 대해 자세히 공부했다면 sigmoid, tanh에 의해 발생하는 문제를 알 수 있을텐데 바로 vanishing/exploding gradient이다.
특히나 RNN은 시퀀스의 길이가 길어질수록 역전파 과정에서 tanh의 미분인 0과 1사이값이 계속해서 곱해지게 되서 입력층에 가까워질수록 gradient는 0에 수렴하게 되어 학습이 거의 이루어지지 못하게 된다.
RNN에서는 이를 Long-Term Dependency Problem(장기 의존성 문제)라고 한다.
2-2.LSTM
구조와 특징
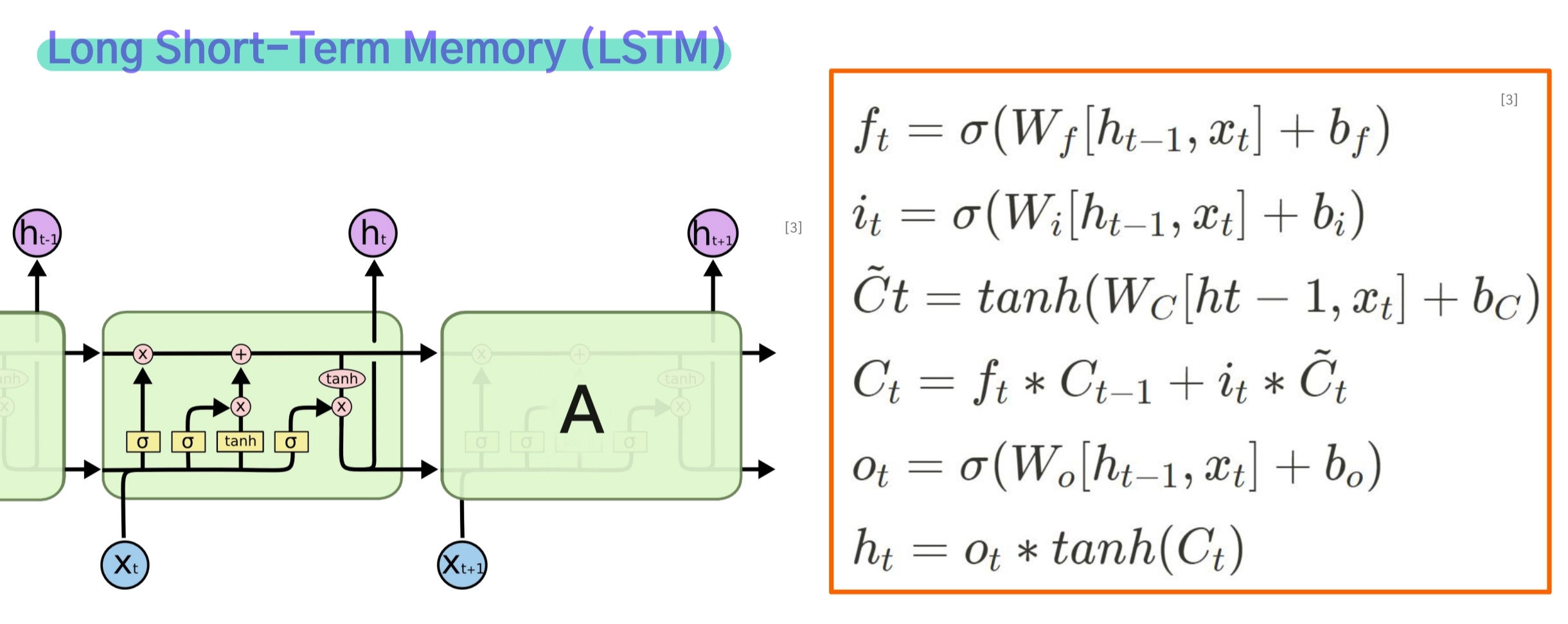
Long-Term Dependency Problem를 해결하기 위해 LSTM이라는 새로운 구조가 개발되었다.
이 모델은 cell state와 gate라는 메커니즘을 도입함으로써 이전 hidden state에서 필요없는 정보를 제거하고, 현재 hidden state에는 꼭 필요한 정보만을 남겨둠으로써 시퀀스 길이가 길어지더라도 보다 좋은 성능을 낼 수 있게 한다.
Forget Gate
- forget gate는 이전 단계의 hidden state와 현재 단계의 입력 $x_t$를 입력 받아 logit을 구하고, sigmoid 함수를 적용해 $f_t$를 구한다.
- $f_t$와 이전 단계의 cell state $C_{t-1}$를 곱해 불필요한 정보를 제거한다.(즉, $f_t$는 계수역할을 한다.)
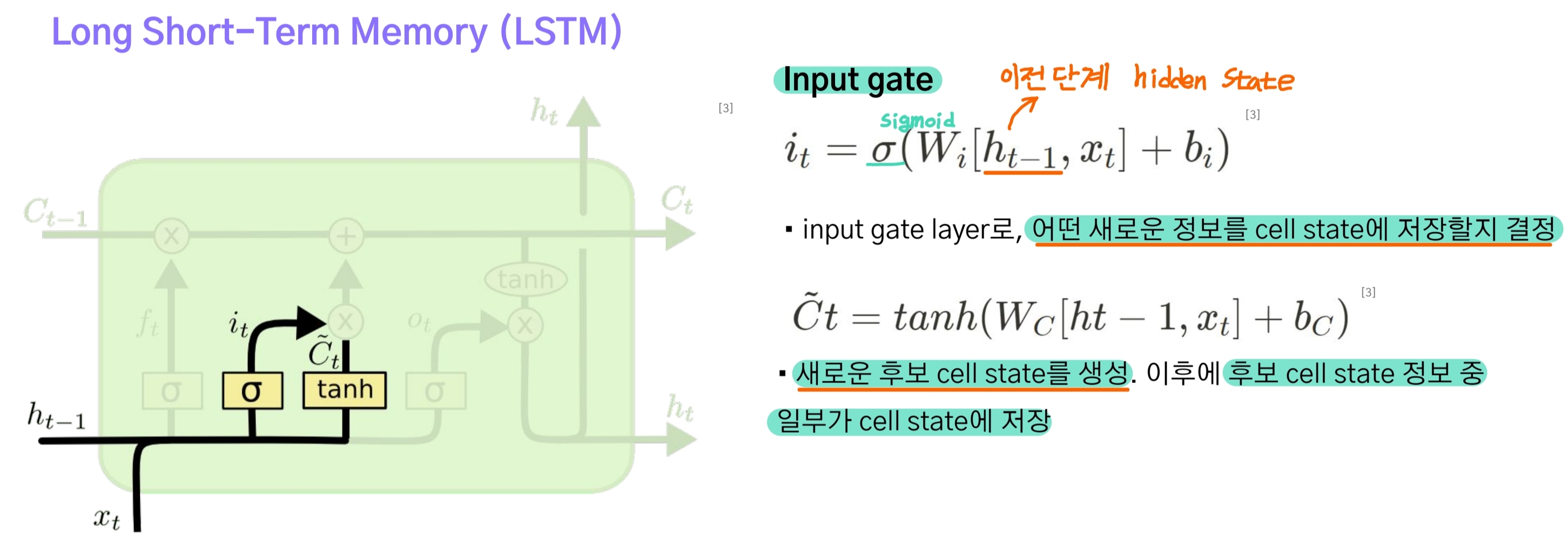
Input Gate
- input gate도 forget gate와 마찬가지로 이전 단계의 hidden state와 현재 단계의 입력 $x_t$를 입력 받아 logit을 구하고, sigmoid 함수를 적용해 $f_t$를 구한다.
- 차이점이라면 $x_t$와 $h_{t-1}$로 구한 현재 단계의 cell state 후보 $ \tilde C_t $에 곱해져 새로 입력된 정보 중 어떤 것을 남겨둘 것인가에 대한 계수로 작용한다.
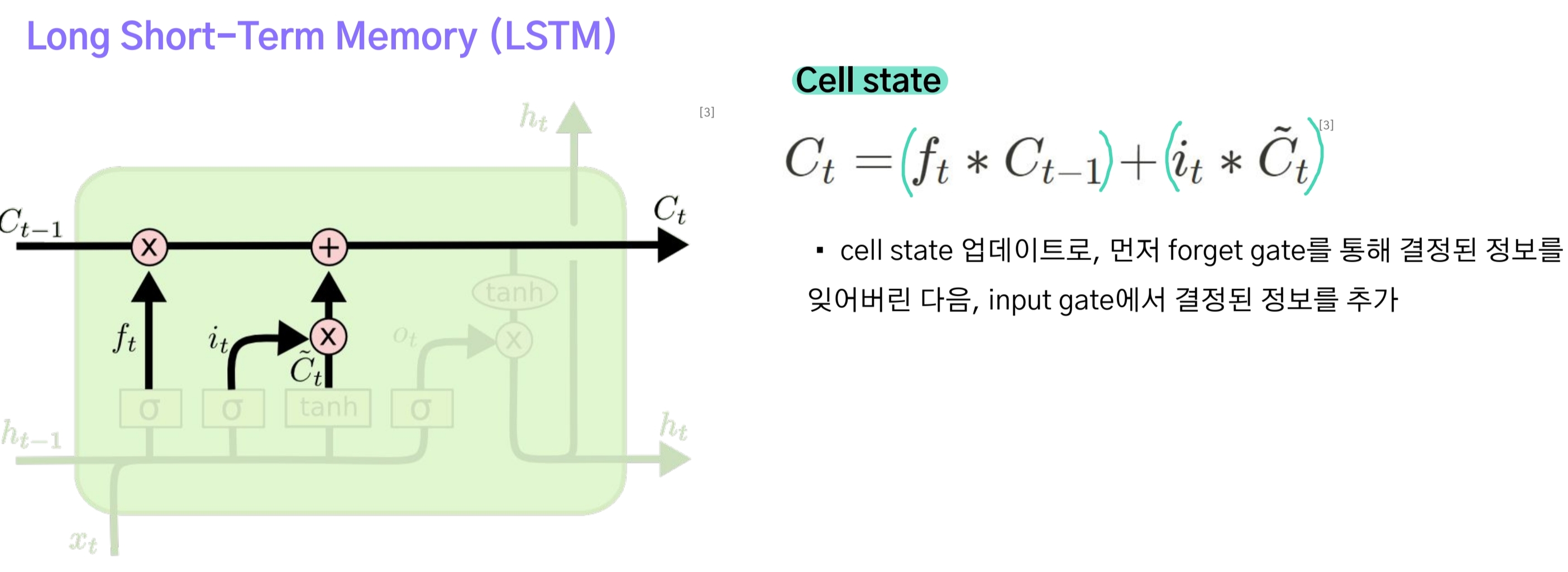
두 개의 gate로부터 얻은 $f_t$와 $i_t$는 각각 이전 단계의 cell state와 현재 단계의 cell state 후보에 적용되고 이들을 더해 현재 단계의 Cell state $ C_t $를 구하게 된다.
Output Gate
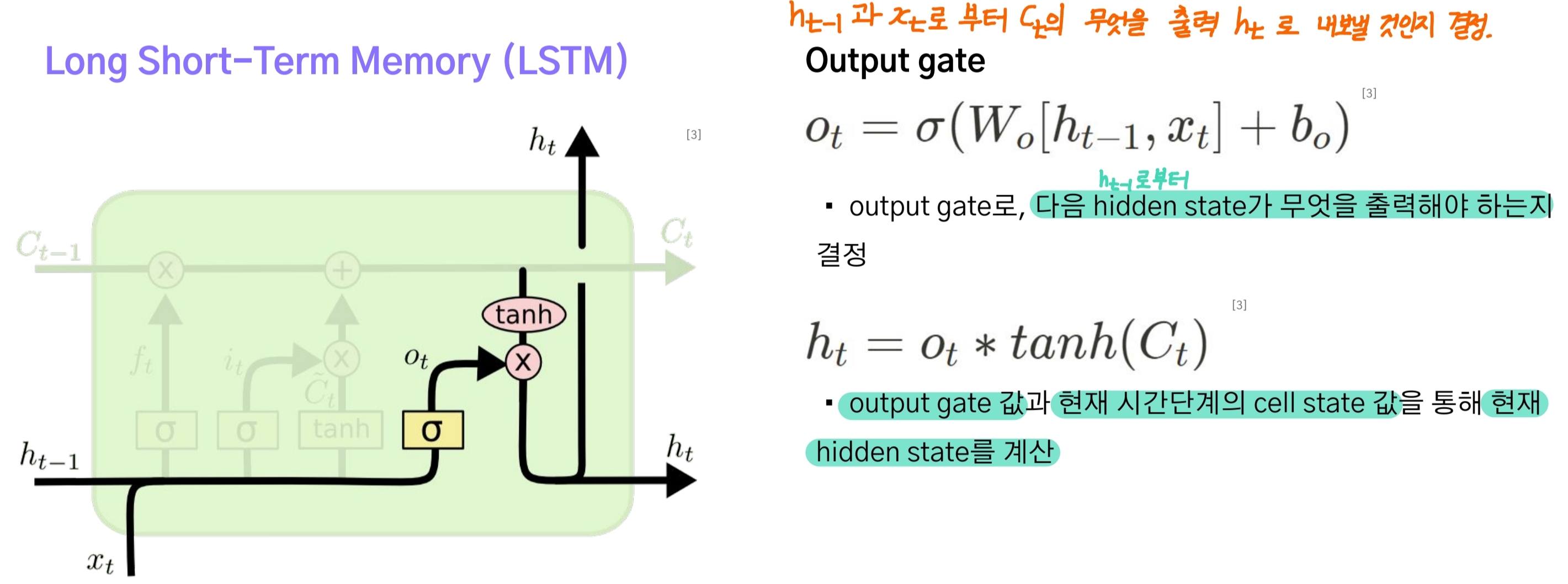
output gate는 이전 단계 hidden state와 입력 $x_t$로부터 계수 $o_t$를 구하고 이를 앞서 구한 현재 단계의 cell state $C_t$에 적용시켜 어떤 값들을 hidden state로써 출력시킬지 결정한다.
2-3.GRU
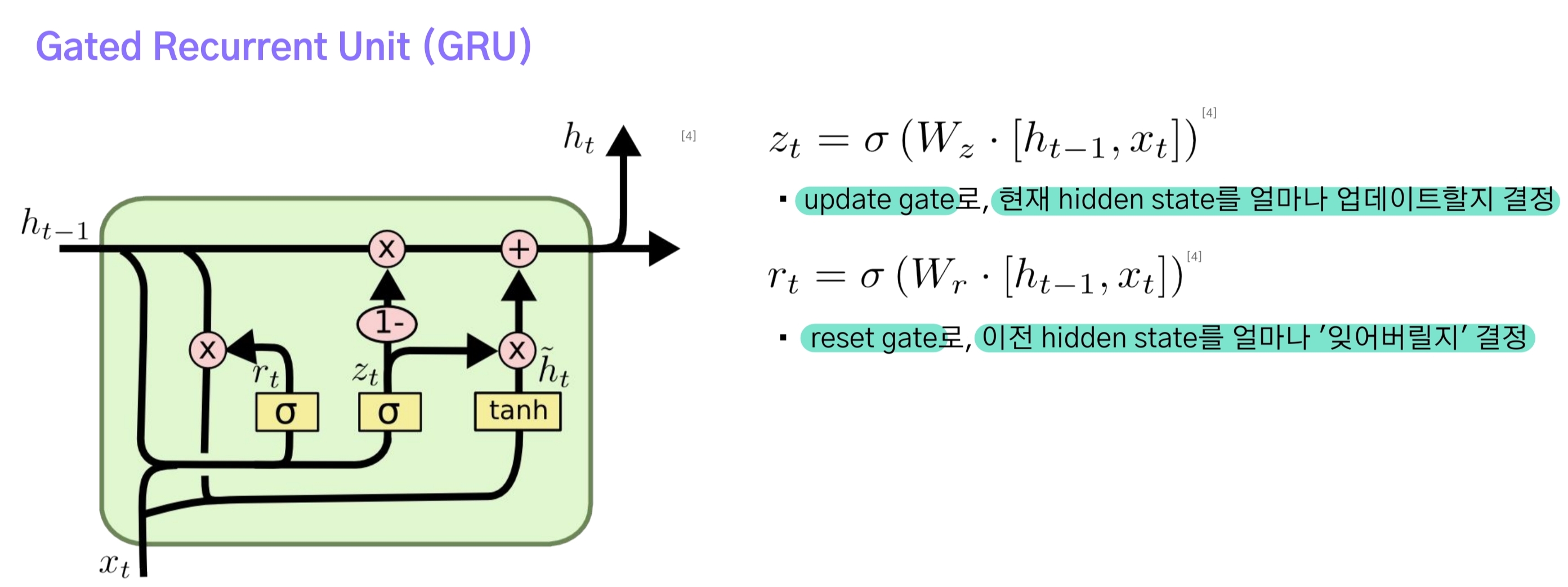
GRU는 LSTM보다 더 간단한 구조를 가지고 있어 계산효율성이 높으나 cell state가 없기 때문에 Long-Term dependency문제에 LSTM보다 취약하다.(Gate는 존재하기 때문에 RNN보다 강건.)
- update gate : 현재의 입력으로부터 이전 Hidden state를 얼마나 업데이트할 것인지 결정하는 계수.
- reset gate : 이전 Hidden state에서 어떤 정보를 잊어버릴 것인지 결정하는 계수.
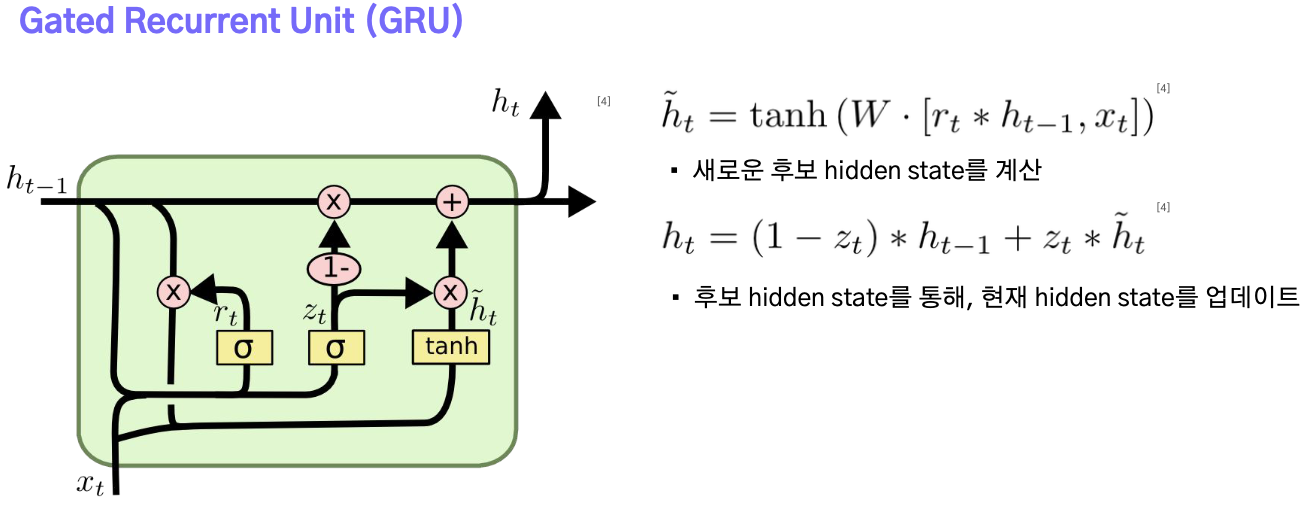
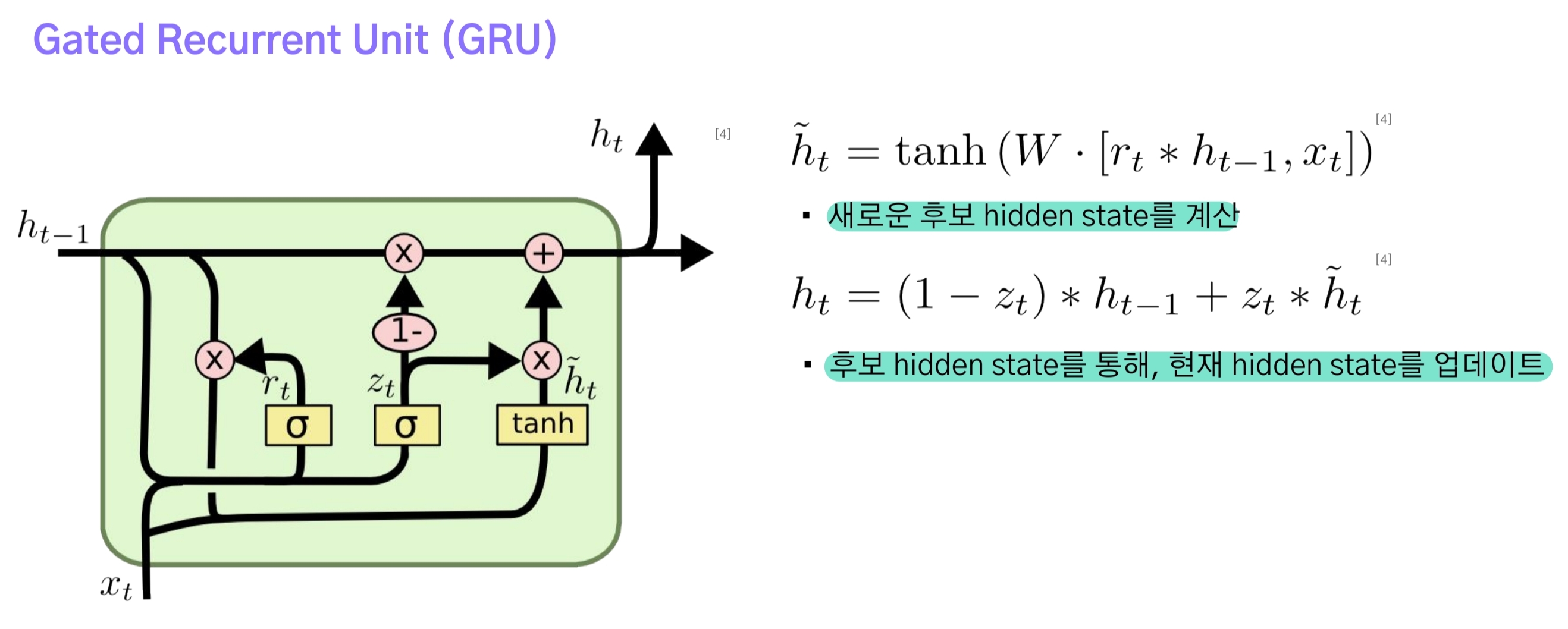
- reset gate의 출력을 이전 단계 hidden state에 곱하고, 새로운 hidden state 후보를 구한다.
- 후보가 갖는 정보들 중 얼마나 현재 hidden state에 반영할 것인지 결정해 $ h_t $를 구한다.
댓글남기기