NLP Pretrained Models
Pretrained Base Language Model
1.Transfer Learning
1-1.등장 배경
문제점1.Word Embedding의 한계
딥러닝 기반 자연어처리는 초반에 Word2vec, Glove 같은 방법으로 단어를 벡터로 맵핑시켜 컴퓨터가 자연어를 이해할 수 있게 하였으며, RNN 계열 모델들을 기반으로 발전되었다.
하지만 이러한 word embedding 방식은 자연어가 가진 모호성을 명확하게 표현하지 못하는 한계가 존재한다.
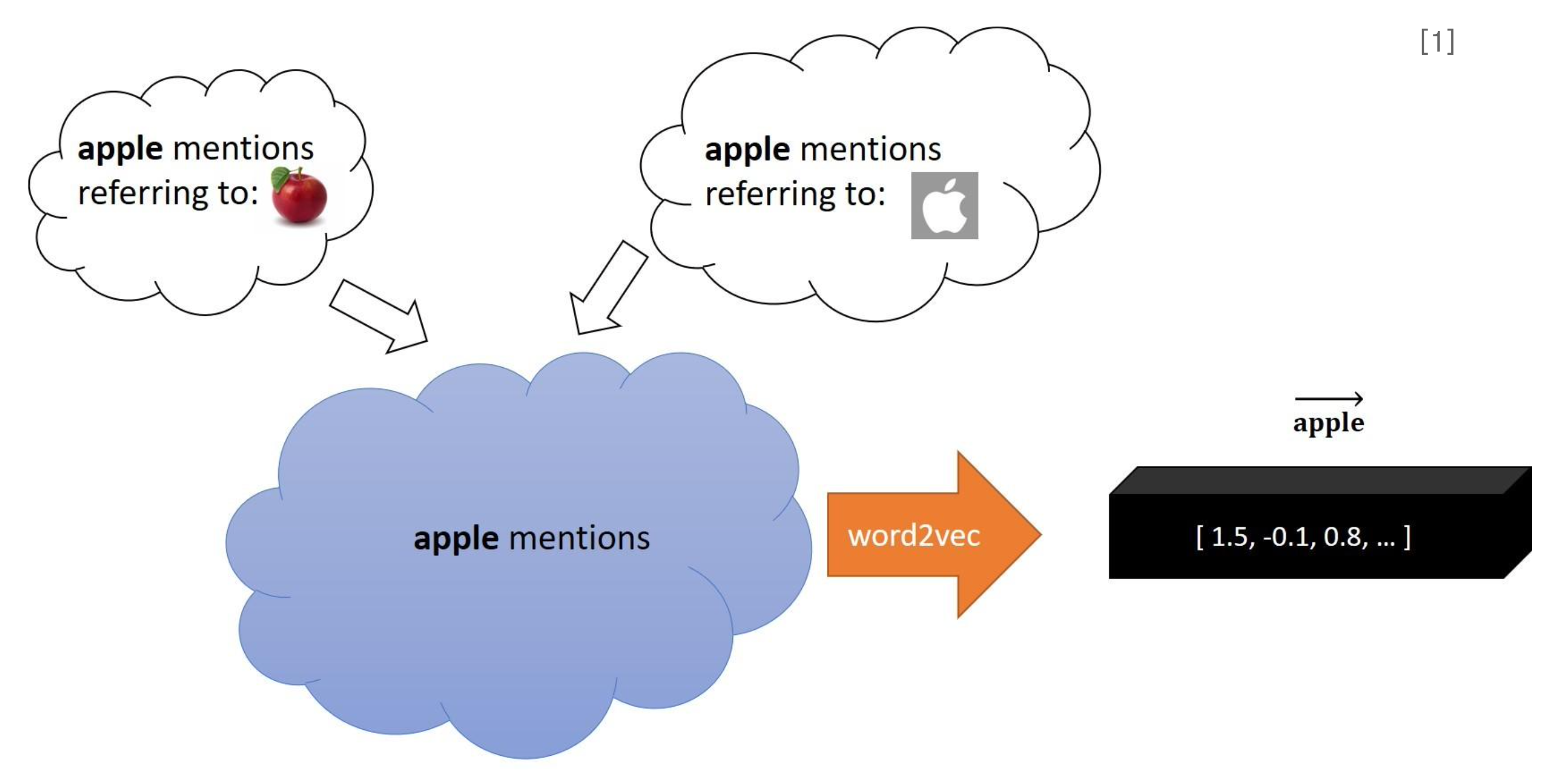
- 동일한 단어임에도 문맥에 따라 다른 뜻을 갖게 되지만 word embedding은 단어가 어디에 나타나든 동일한 벡터로 맵핑한다.
- 한 번에 여러 의미를 갖는 다의어는 하나의 의미만 살아남아 벡터로 맵핑된다.
- 즉, 기존의 word embedding 방식이 같은 문제를 해결하기 위해 문맥으로부터 단어의 의미를 파악해서 벡터로 맵핑하는 새로운 Embedding 방식이 필요하다.
문제점2.대규모 학습 데이터셋 필요.
- 딥러닝의 특성상 모델 학습에는 충분히 많은 양의 데이터가 필요하다. 뿐만 아니라 자연어처리 하위분야인 텍스트 분류, 질의응답, 요약문 생성과 같은 작업들을 실제 사용가능한 수준까지 성능을 높히려면 대규모 데이터셋이 필요하다.
- 풀려고 하는 문제마다 labeled dataset을 준비하기에 시간이 너무 오래걸리고 비용 또한 크다. 이는 의료, 법률과 같은 전문적인 분야에 있어 더 큰 문제로 작용되었다.
- 뿐만 아니라 데이터가 준비되었다 해도 매번 모델을 처음부터 학습하기 위해 시간과 자원 소모가 굉장히 크다.
- 특정 도메인의 데이터로 학습된 경우 다른 도메인에 대한 성능은 굉장히 떨어진다. 즉, 도메인을 구분하지 않으면서 일반화 성능이 높아야 하는데 이는 매우 어려운 문제다.
1-2.NLP와 Transfer Learning
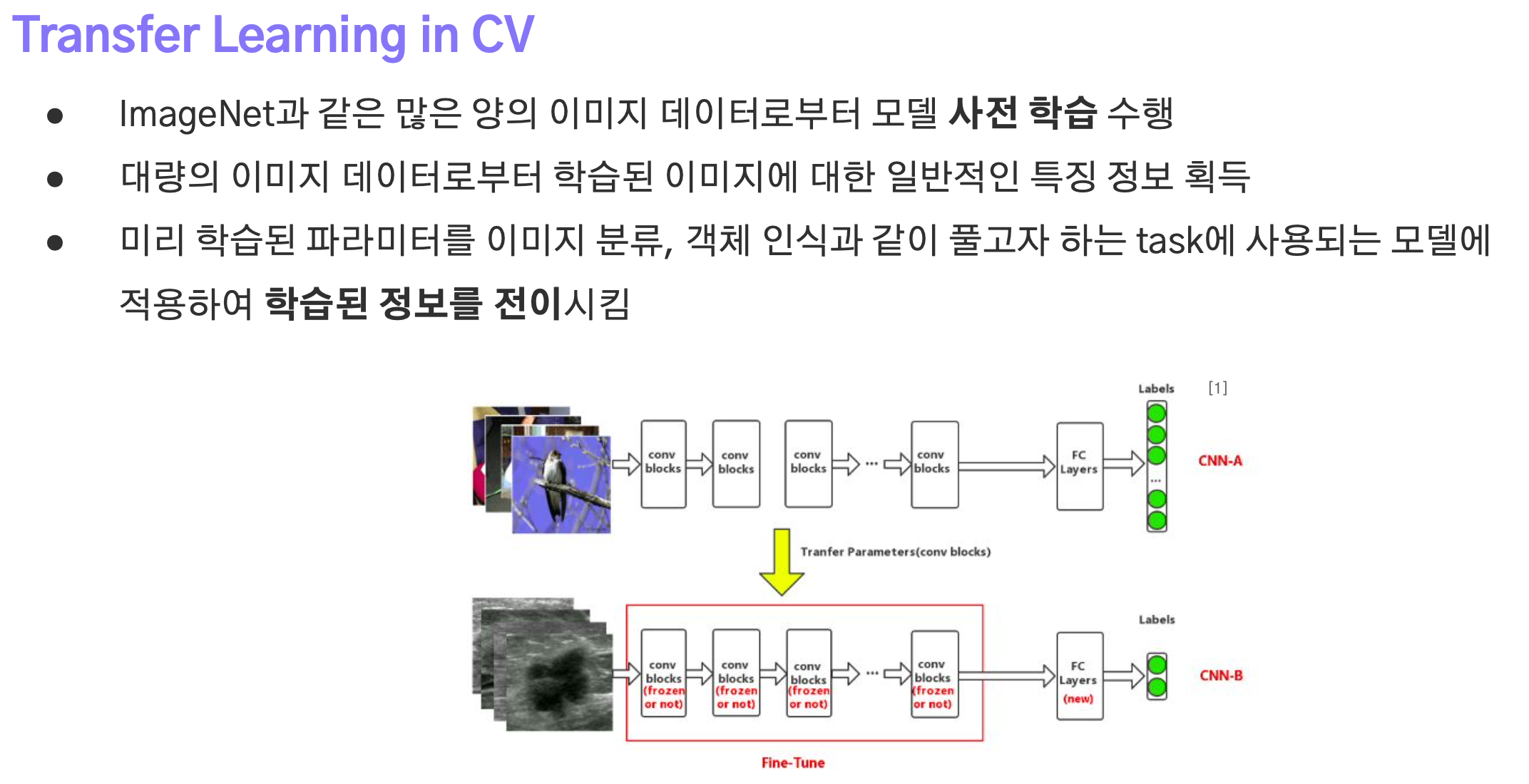
전이학습은 특정 도메인 task로부터 학습된 모델을 비슷한 도메인 task 학습에 재사용하는 기법으로 원래 ImageNet 데이터셋 기반의 컴퓨터비전 분야에서 주로 활용되었다.
대규모 데이터셋으로 학습된 모델을 backbone으로 활용함으로써 Object Detection, Segmentation과 같은 추가 작업의 성능을 높힐 수 있었으며, pretrained로 인해 비교적 짧은 학습으로도 좋은 성능을 낼 수 있었다.
따라서 전이학습을 NLP task에 활용할 수 있다면,
- 대량의 Corpus를 활용하며 특정 방식으로 모델을 사전학습한다.
- 이는 언어가 갖는 전반적인 특징 정보를 학습한 Pretrained Model을 얻기 위함이다.
- 또한, Pretraining에서 사용되는 대규모 데이터셋은 label이 없다. 따라서
Self-Supervised Learning을 수행한다. - 학습 모델은 Trainable Embedding Layer를 포함하고 있기 때문에 시퀀스 데이터를 학습하면서 각 토큰들을 벡터로 맵핑할 때 문맥에 따른 의미를 반영할 수 있게 된다.
- 또한, Pretraining에서 사용되는 대규모 데이터셋은 label이 없다. 따라서
- 사전학습된 모델을 풀고자하는 task로 fine-tuning한다.
즉, pretrain을 통해 자연어 자체가 갖는 특징들을 먼저 학습한 후 downstream task에서는 해당 문제에 맞는 지식을 학습하면 되니 문제를 이전보다 간단하게 해결할 수 있고, 학습 데이터의 양과 학습 시간도 줄일 수 있게 된다.
뿐만 아니라 비지도 학습을 수행하기 때문에 인터넷에서 크롤링한 대규모 데이터들을 학습에 사용할 수 있다는 굉장히 큰 이점이 존재한다.
2.BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2-1.개요
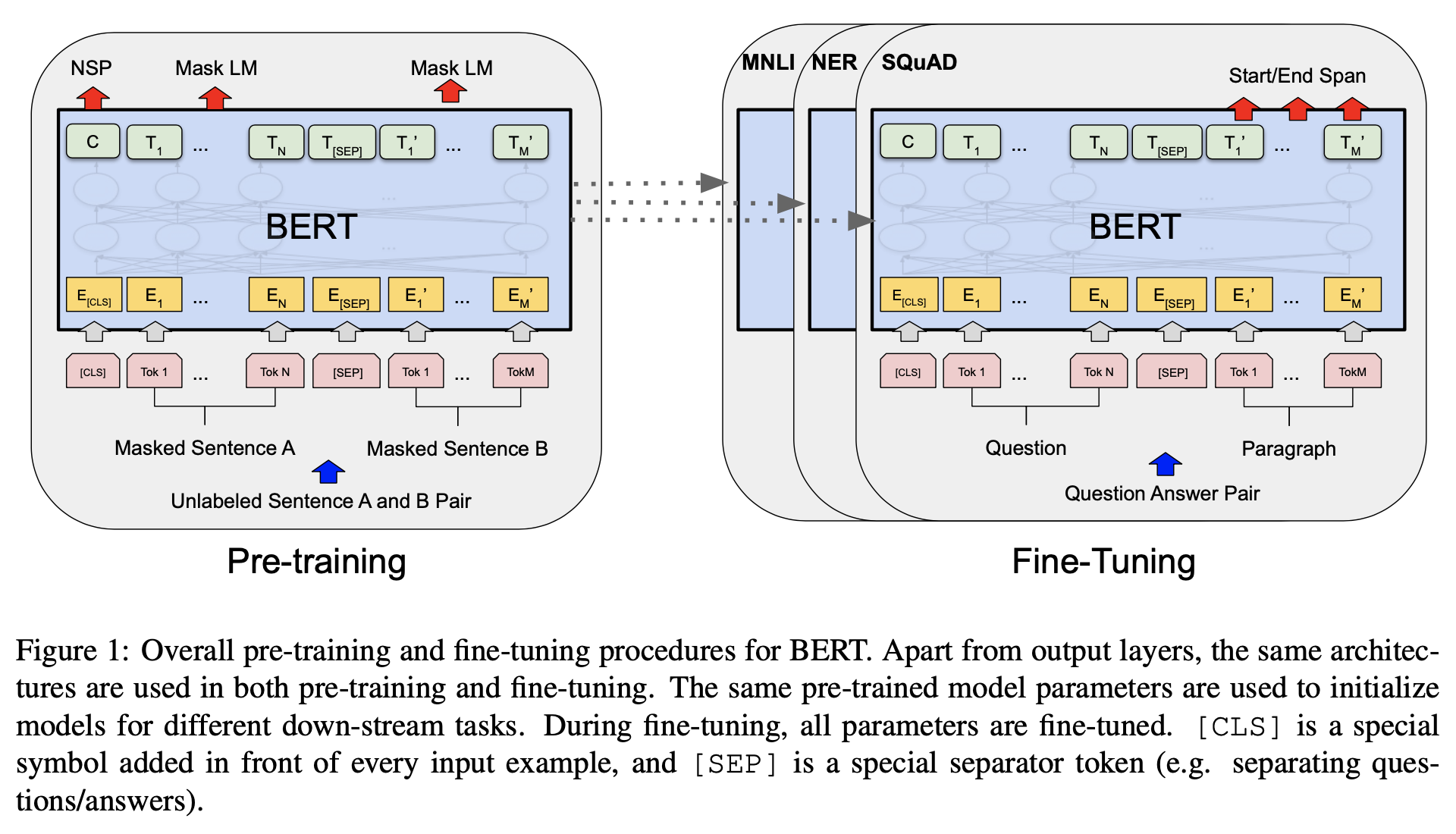
bert는 transformer의 인코더만으로 구성된 Language Model이다.
- 문장에서 무작위로 단어를 마스킹하여 양방햔 단어 정보를 동시에 학습한 문맥 정보를 습득하게 된다.
- 뿐만 아니라 위키피디아와 BooksCorpus와 같은 label이 없는 텍스트 데이터로 Pretraining을 한다.
- pretrained bert를 downstream task에 적용하여 fine tuning을 수행한다.
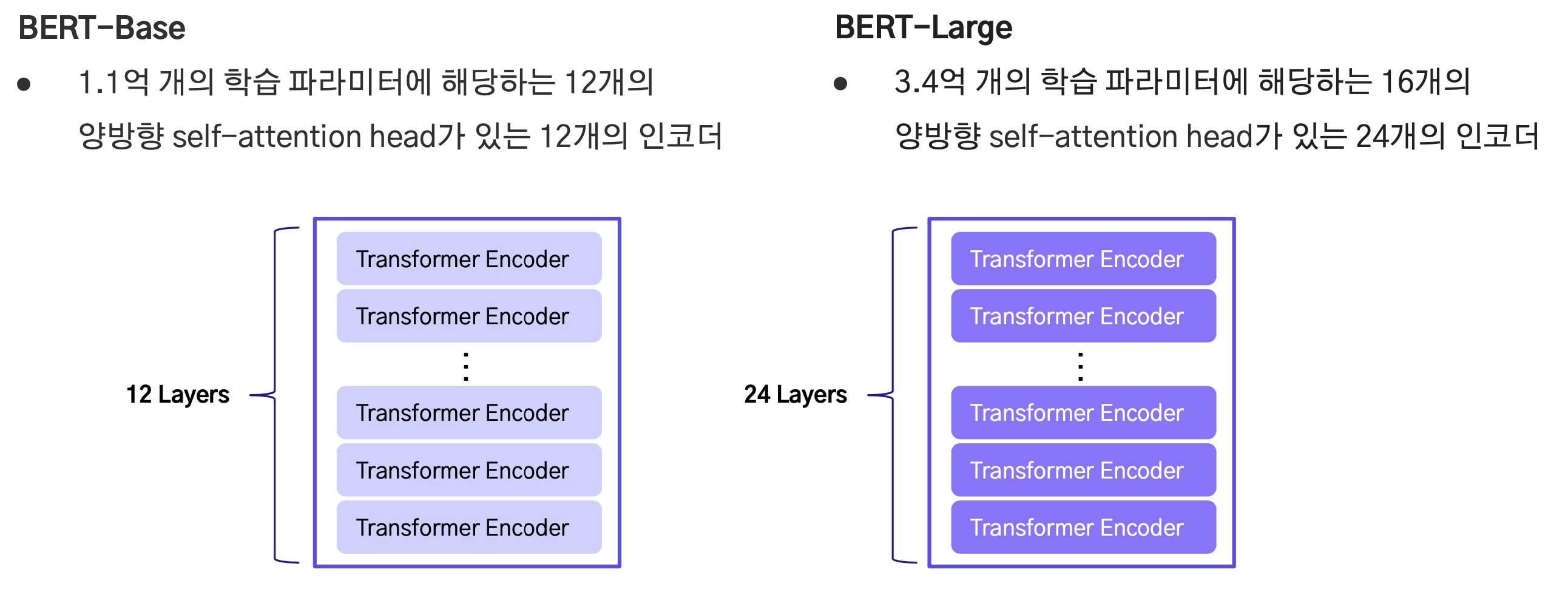
bert는 base와 large 버전이 존재하는데, 구조는 transformer encoder only로 동일하지만, encoder layer의 수가 각각 12개, 24개 그리고 self-attention headrk 12개, 16개라는 차이점만 존재한다.
구조적인 특성을 보면 결국 BERT는 자연어 이해(NLU)를 핵심적으로 학습하고, downstream task에 적용되어 높은 성능을 낼 수 있게 하는 것이 주된 목적임을 알 수 있다.
2-2.구조
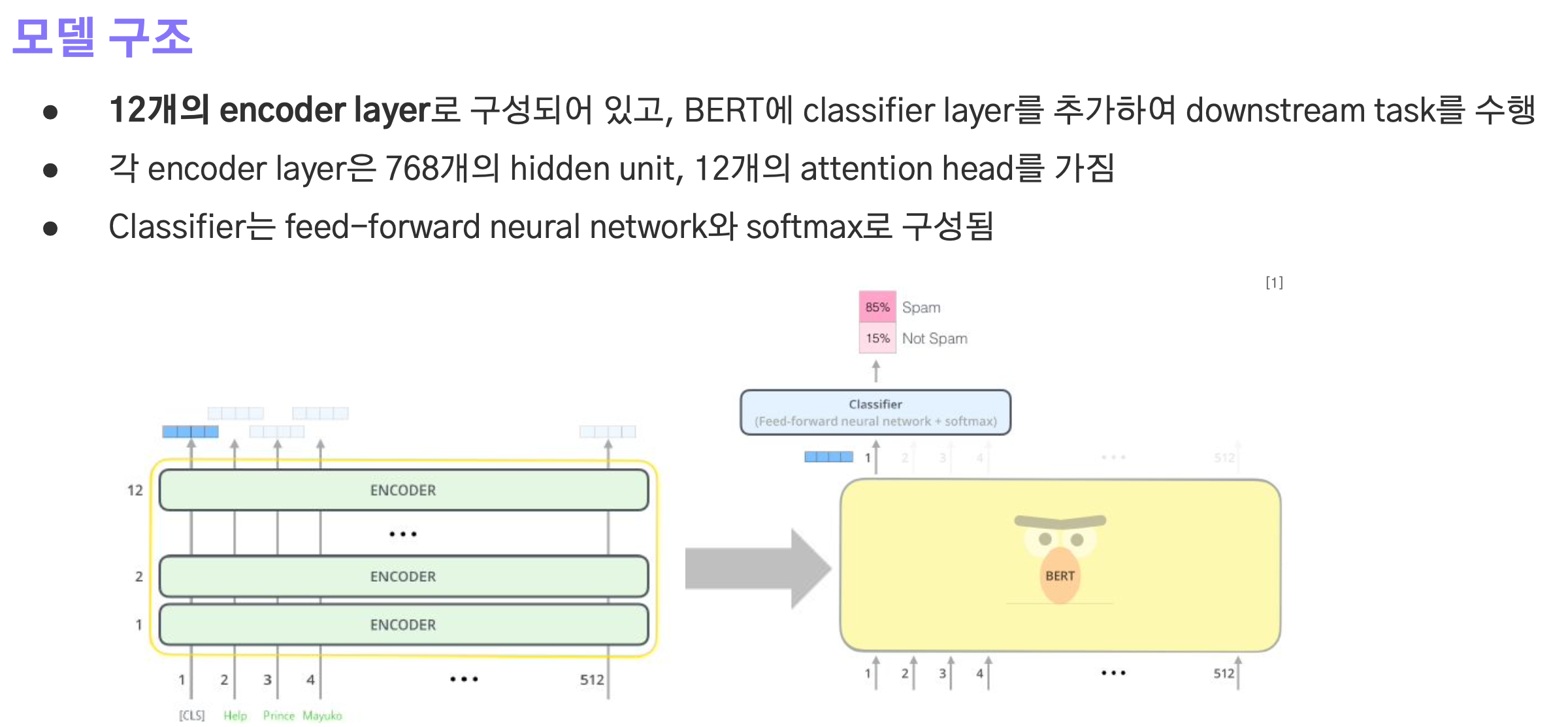
- bert는 12개의 encoder layer로 구성되어 있으며, classifier layer를 추가해 downstream task를 수행하게 된다.
- 각각의 encoder layer는 768차원으로 입출력의 크기가 설정되며 12개의 attention head를 갖는다.
- classifier는 feed-forward network와 softmax로 구성된다.
2-3.연산
Embeddings
bert에 입력되는 시퀀스 데이터에는 CLS, SEP 토큰들이 적용된다.
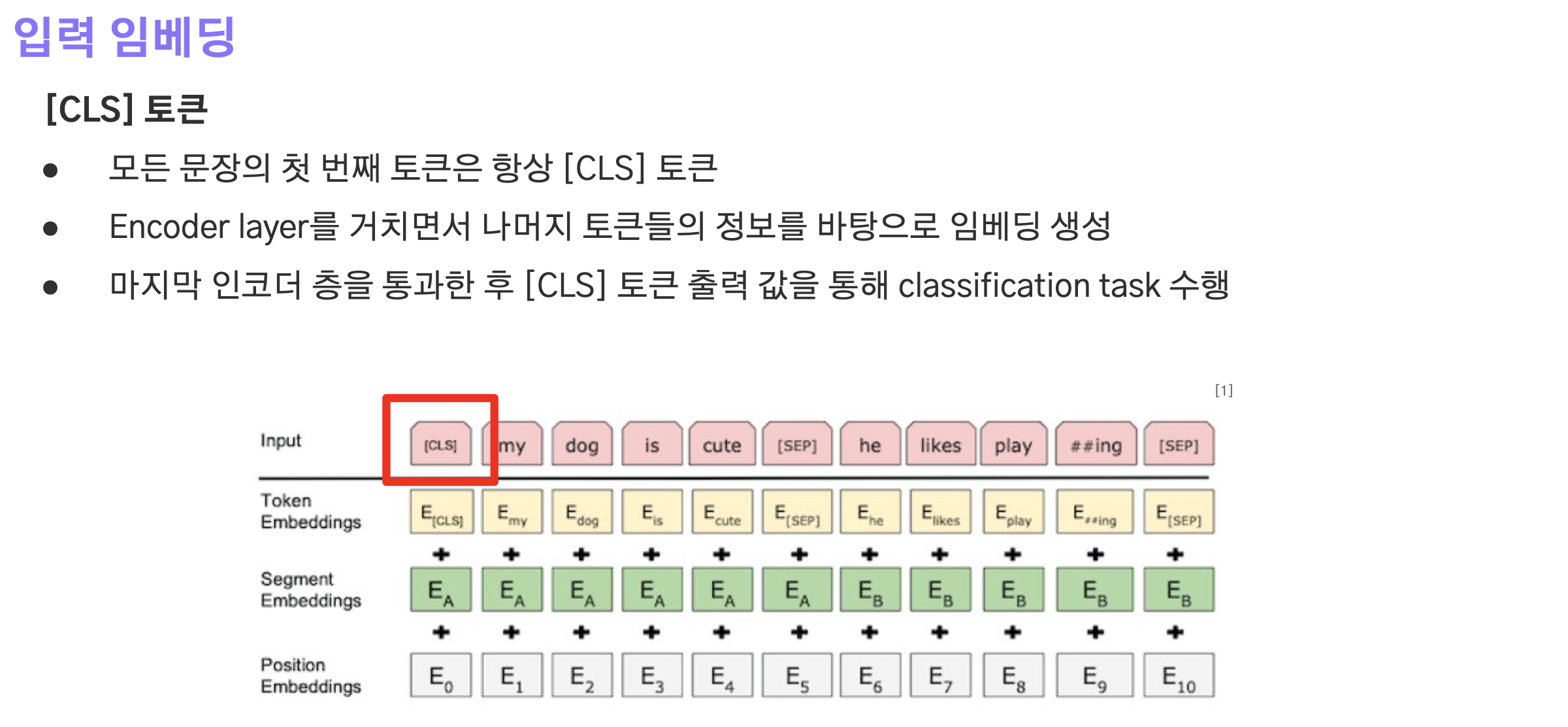
CLS 토큰
- 모든 시퀀스(문장)의 맨 앞에 추가되는 토큰.
- encoder layer를 통과하면서 다른 토큰들의 정보를 바탕으로 임베딩 값이 만들어지게 된다.
- 마지막 encoder layer를 통과한 후 CLS 토큰의 임베딩 벡터를 통해 classification task를 수행한다.
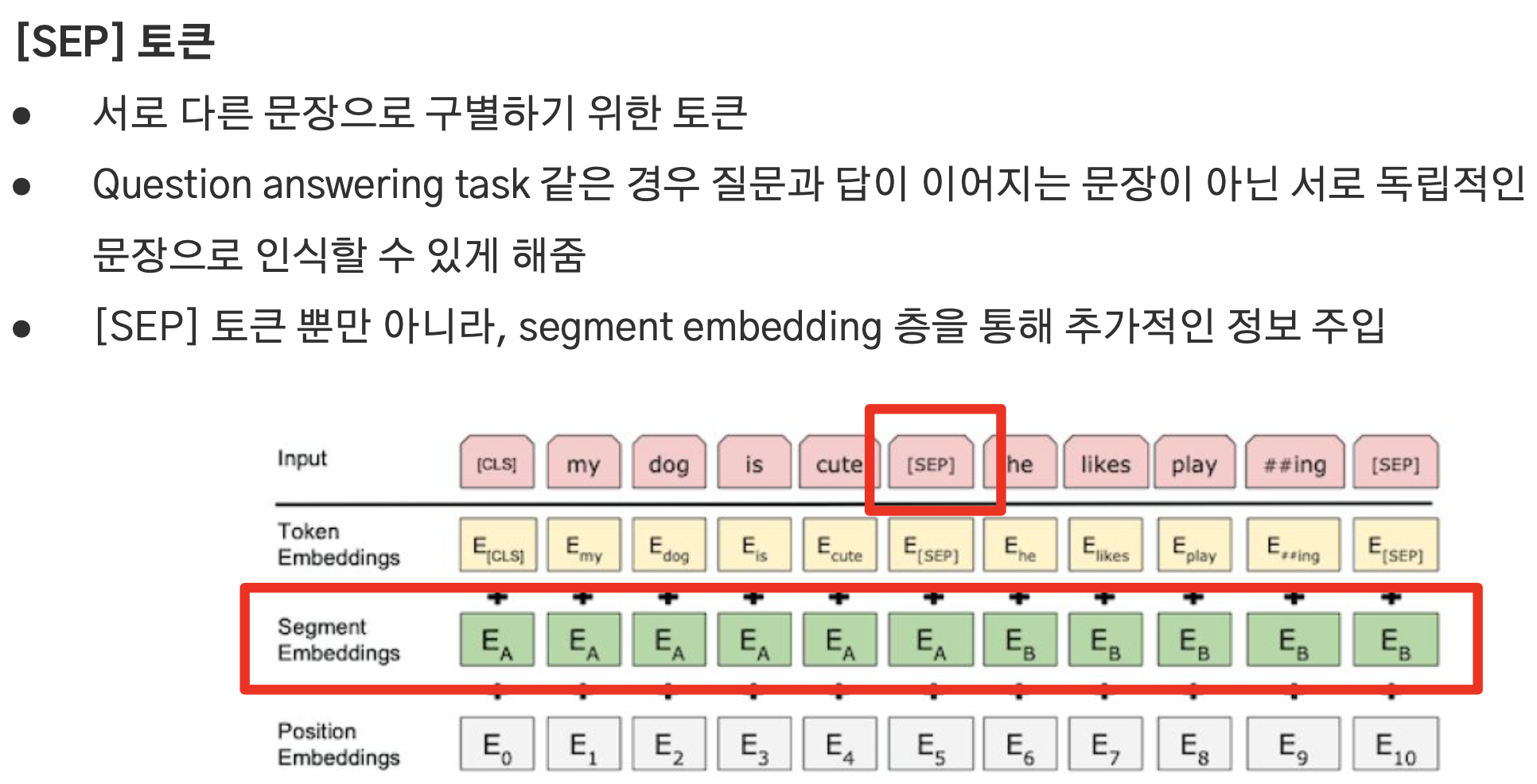
SEP 토큰
- 서로 다른 문장을 구분하기 위한 토큰.
- 연속되는 문장들 사이에 추가하여 이어지는 문장이 아닌, 서로 독립적인 문장임을 모델이 인식할 수 있게 하기 위해 사용.
Input Embedding
- 이후, 시퀀스 데이터에는 token embedding, segment embedding, position embedding이 적용되며 세 개의 벡터를 더한 결과가 모델에 입력되는 최종 임베딩 벡터다.
- token embedding : 단어(토큰)들을 벡터로 맵핑하는 역할.
- segment embedding : 질문과 정답 또는 원문과 요약처럼 연결되는 문장들을 구분하기 위함이다. 학습을 통해 SEP 토큰 이전에는 0, 이후에는 1을 부여함으로써 문장들을 구분할 수 있게 한다.
- position embedding : 트랜스포머에서는 cos, sin 함수를 사용해 시퀀스 내 토큰들에 위치 정보를 반영했으나, bert에서는 학습 가능한 embedding을 적용한다.
Encoder layers
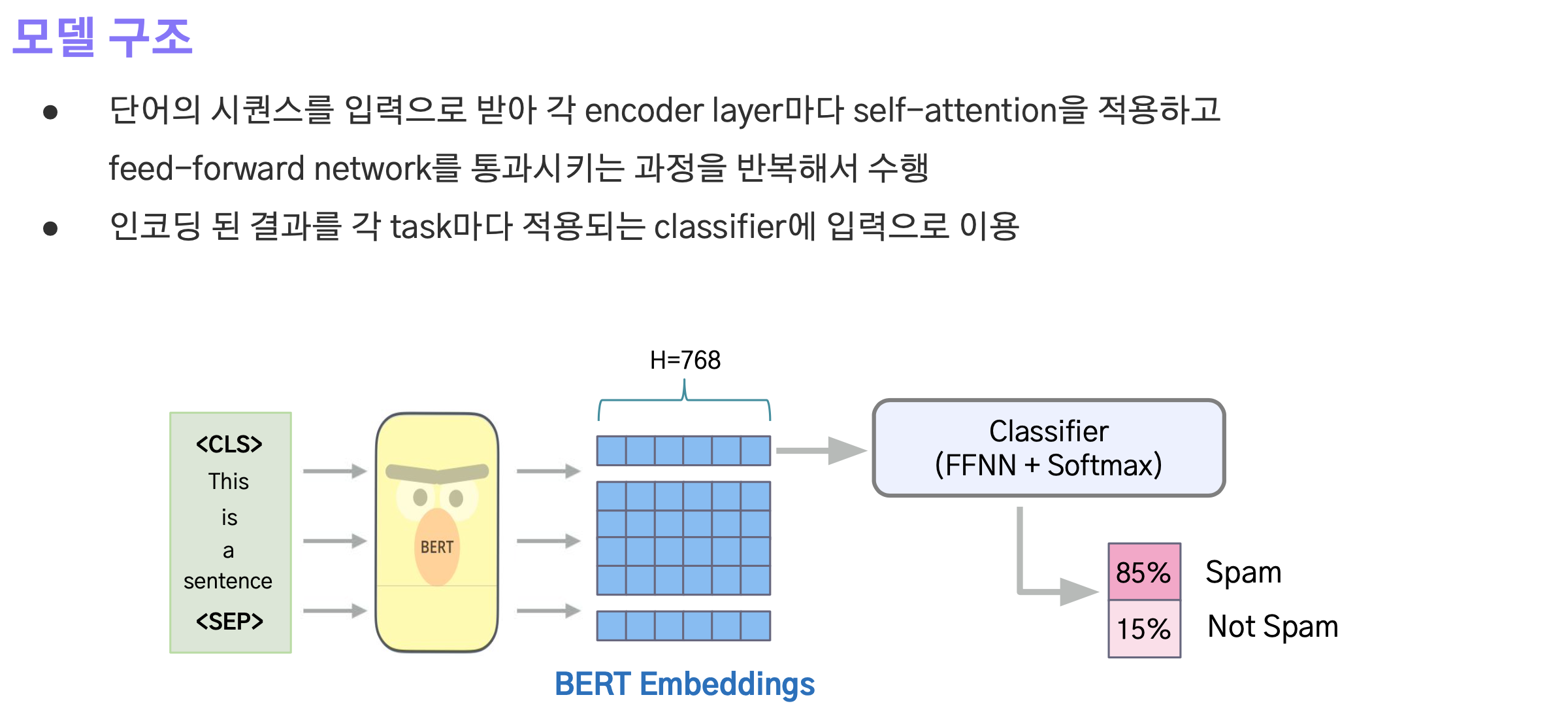
Encoder로 입력된 임베딩은 self-attention과 feed-forward network를 통과하는 과정을 반복적으로 수행한다.
최종적으로 인코딩 된 결과에서 첫번째 벡터는 CLS 토큰 임베딩에 대한 벡터이며 이를 classifier(FFN + Softmax)에 입력해서 분류 결과를 획득한다.
2-4.Pretrain
Masked Language Model
bert는 대규모 unlabeled data를 사용하는 self-supervised learning을 통해 사전학습을 하게 된다.
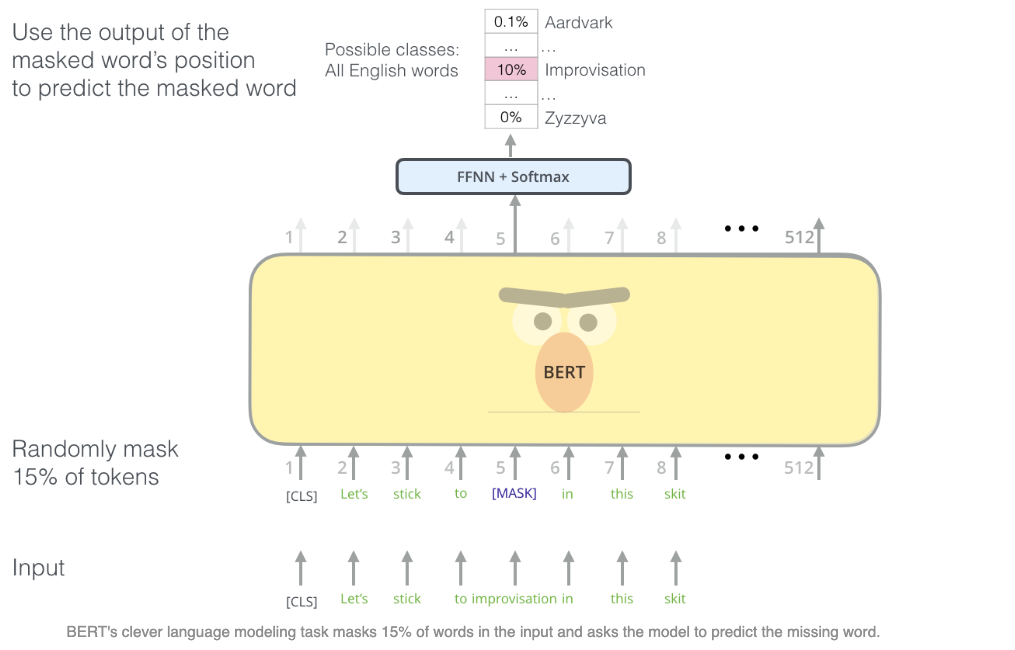
첫번째 task는 MLM이다. 이 task는 문장 내에서 무작위로 일부 토큰들을 MASK 토큰으로 변경하고 학습을 통해 MASK에 들어갈 적절한 단어 토큰을 예측하도록 하는 것이다.
즉, label은 별도로 만들지 않았지만 어떤 단어가 마스킹되었는지 이미 알고 있기 때문에 label을 가지고 있는 상태로 self supervised learning을 할 수 있는 것이다.
- 각 문장마다 토큰의 15% 중 80%는 MASK 토큰으로 변경, 10%는 무작위로 다른 단어로 변경, 나머지 10%는 그대로 둔다.
- 마지막 encoder layer의 출력 중 MASK 토큰에 해당하는 벡터를 softmax 함수에 통과시켜 단어를 예측.
- 이를 통해 양방향 단어 정보 즉, 문맥을 기반으로 한 언어적인 이해를 학습할 수 있게 된다.
Next Sentence Prediction
두번째는 NSP로, 두 개의 문장이 실제로 연결되는 문장인지 예측하는 task이다.
- 두 개의 문장을 제공하고 이들이 실제로 이어지는 문장인지 예측하는 LM 학습.
- 두 문장이 서로 어떤 관계에 있는지를 추론하는 Question & answering 같은 문제를 해결할 수 있게 한다.
- 앞서 문장과 문장 사이에 SEP 토큰이 적용되었는데, 이것이 곧 각 문장이 서로 다른 문장임을 알려주는 역할을 한다.
- 학습을 위해 50%는 실제 연결되는 문장들, 나머지 50%는 임의로 선택한 문장으로 구성한다.
- 가장 앞에 위치한 CLS 토큰으로 두 문장이 이어지는 문장인지 예측.
3.Fine-Tuning
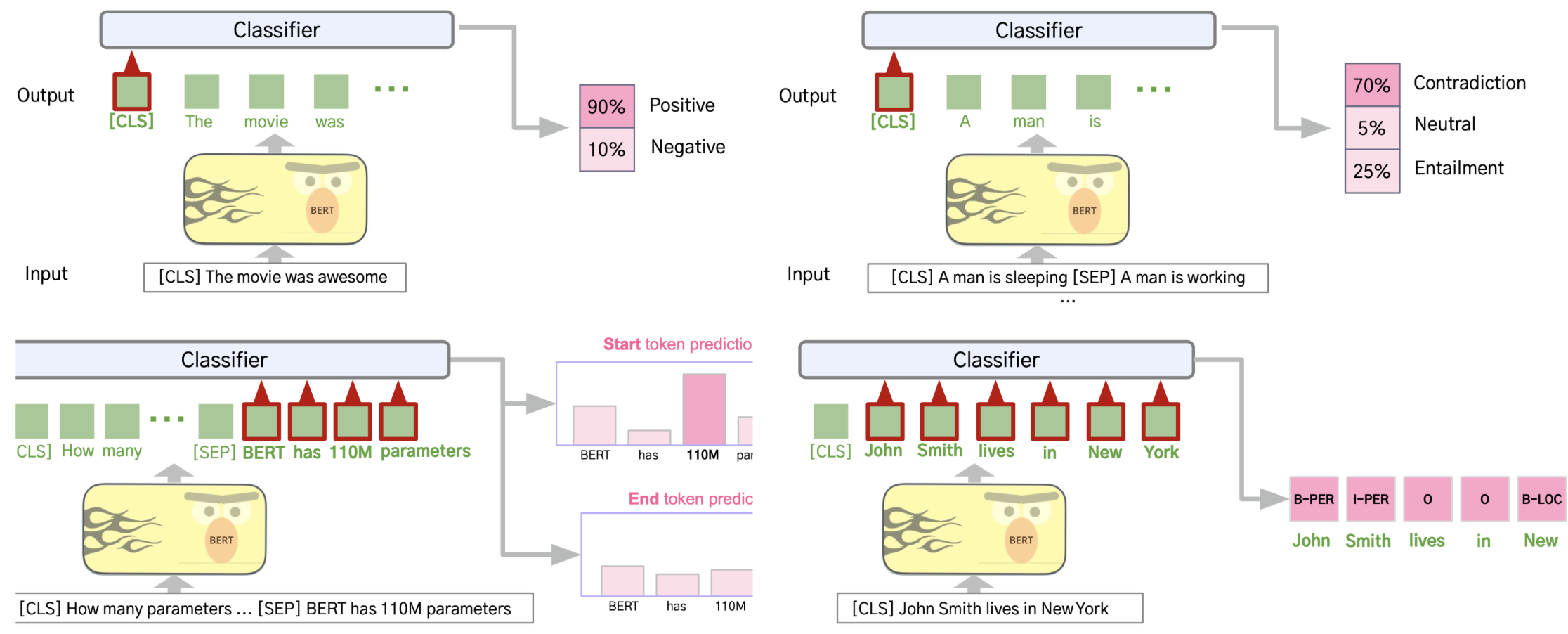
사전 학습된 bert를 이용해 풀고자 하는 task로 fine tuning을 수행한다.
이 때, Backbone인 bert는 그대로 두고, task에 맞는 출력을 만들어 내기 위한 작은 NN을 추가함으로써 학습 및 추론을 수행한다.
여기서 한 가지 알 수 있는 점은 비록 BERT가 출간되어 Pretrained Weight를 사용할 수 있게 되었고 그에 따른 여러 장점들이 존재하지만, task별로 별도의 모델이 필요하다는 점은 여전히 문제로 남아 있는 상태다.
3.GPT
3-1.GPT-1
Improving Language Understanding by Generative Pre-Training
GPT는 Bert처럼 대규모 데이터셋을 사전학습함으로써 언어를 이해하게 되며 이를 downstream task에 적용하는 방식이다.
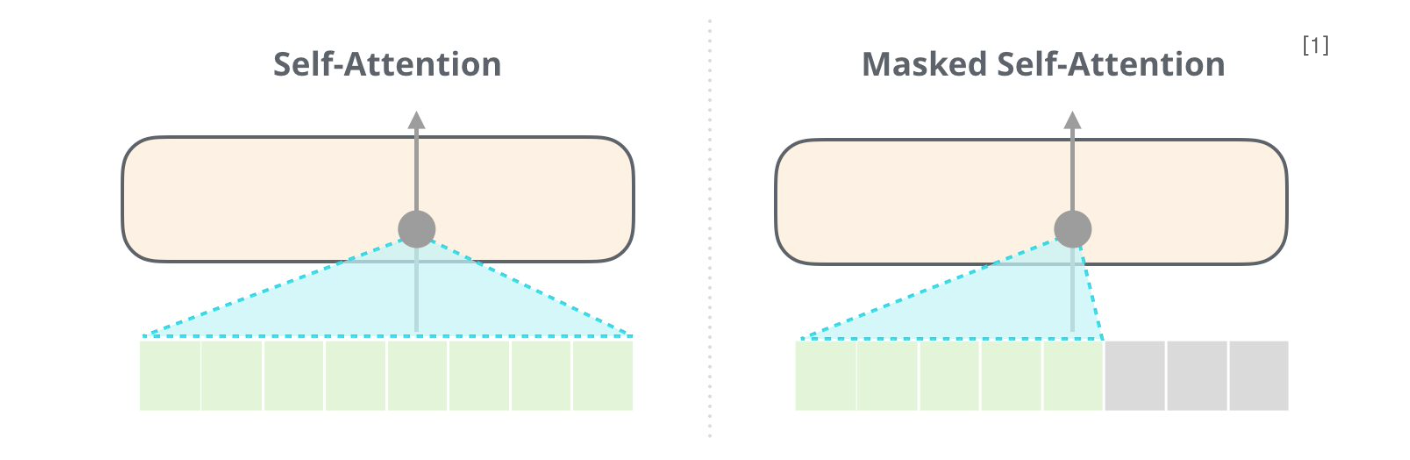
- Transformer의 Decoder로 구성.(Multi layer Transfomer Decoder)
- Bert의 Masked Language Modeling과 다르게 다음 단어를 생성하는 방식으로 pretrain이 진행된다.(이를
Casual Language Model이라한다.) - 즉, bert는 양방향으로 문맥을 이해하지만 gpt는 문장의 흐름대로 앞부분의 문맥을 보고 다음에 올 단어를 예측하는 단방향(undirectional) 학습을 수행한다.
- 40000개 단어에 대한 BPE 토크나이저와 단어집을 구축.
- Positional Embedding 사용.
중요한 점은 트랜스포머 decoder에서 수행되는 Self-Attention은 Masked Self-Attention으로, 미래 정보를 반영하지 못하게 마스킹하기 때문에 예측하는 단어의 앞단어만을 반영해 예측을 하는 것이다.

따라서 gpt 모델은 N개의 토큰으로 구성된 문장을 입력으로 받아 N+1개의 토큰으로 구성된 시퀀스를 생성하게 된다.
- 가장 먼저 sos토큰이 입력되고, 다음으로 올 단어를 생성한다.
- 이후 eos 토큰을 생성하거나 출력 시퀀스의 최대길이에 도달하면 생성을 종료한다.
- 기계번역을 수행하는 트랜스포머 모델이 추론 과정에서 번역문을 생성할 때처럼 eos 토큰을 생성할 때까지 반복.
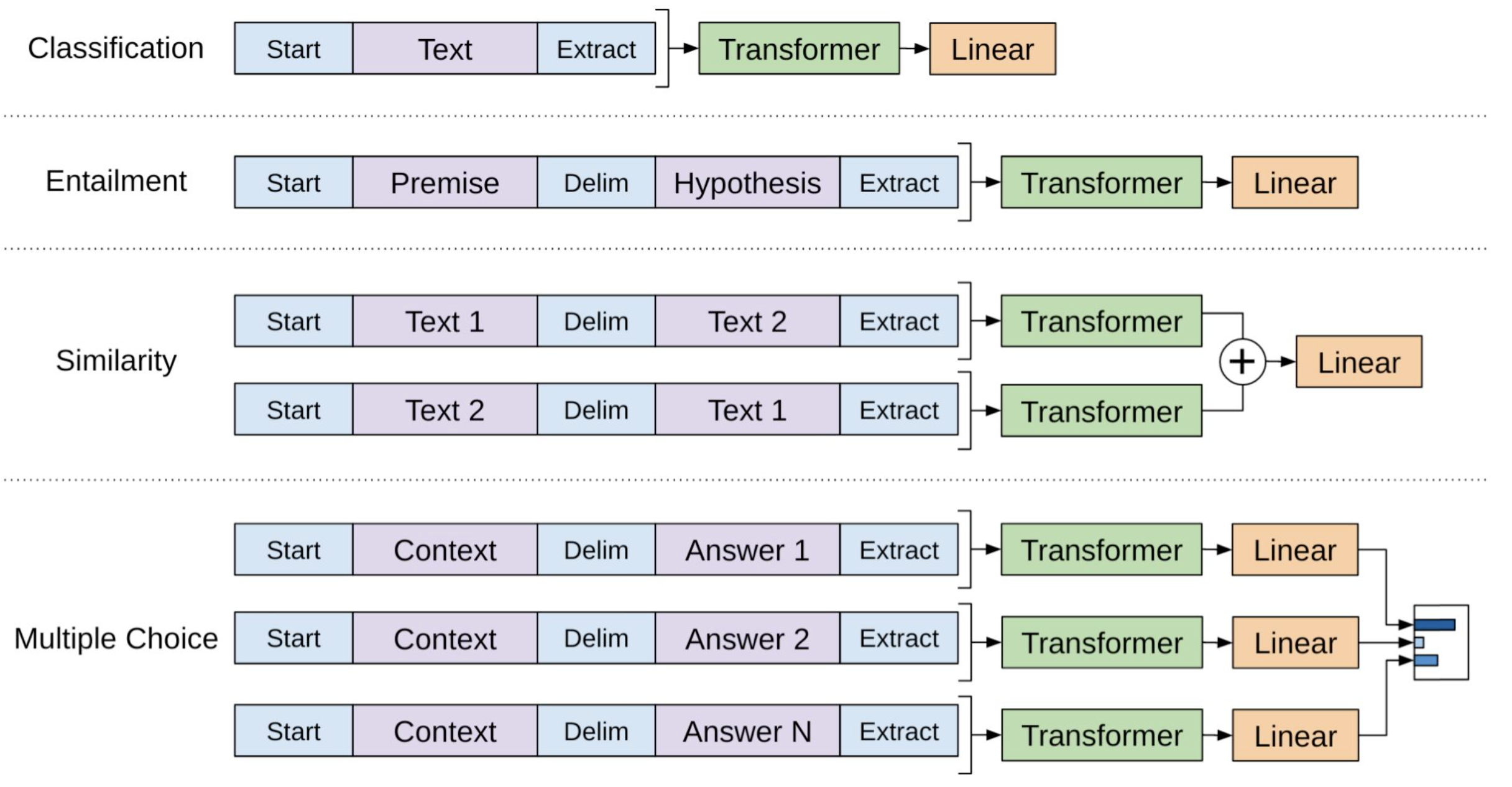
- Fine-tuning 단계에서는 task에 맞게 입력을 $토큰을 통해 하나의 문장으로 변환한다.
- 사전학습 모델에 최소한의 변경만으로 효과적인 fine-tuning 가능.
- Bert와 마찬가지로 task별 labeled dataset과 fine-tuned model이 필요하다.
3-2.GPT-2 & GPT-3
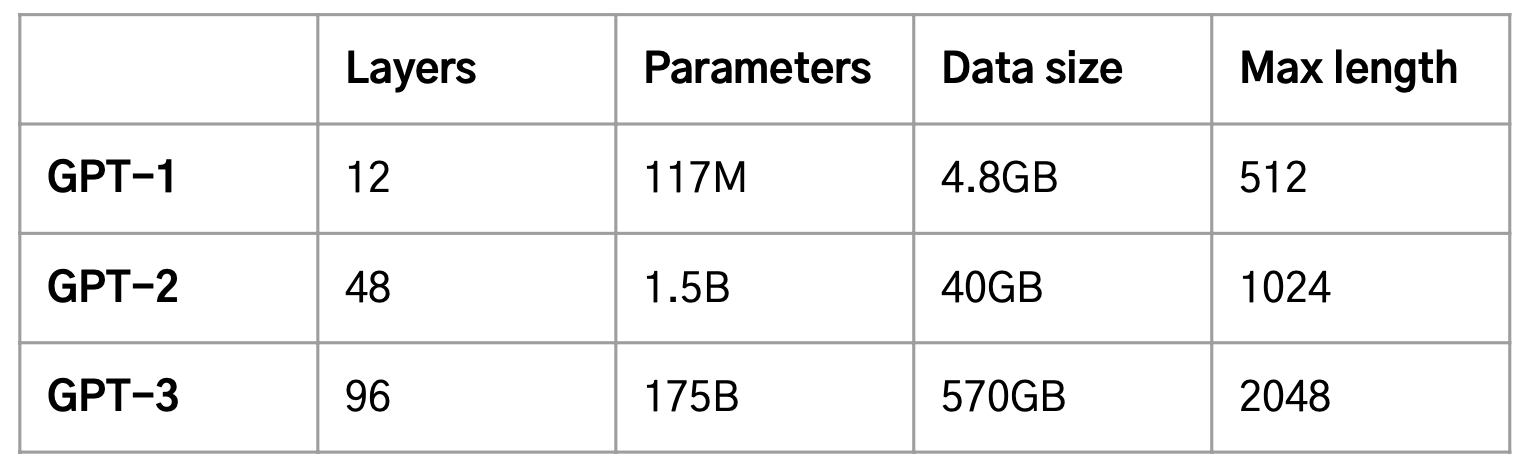
GPT-2, GPT-3는 GPT1과 동일한 Transformer Decoder Layer 구조지만, 더 많은 Layer와 데이터를 사용해 Pretraining을 진행한다.
- 규모를 확장하는 궁극적인 목적은 하나의 모델로 여러 개의 task를 수행하기 위함이다.
- 즉, Multi-task Learning처럼 여러가지 task를 동시에 학습시킨 하나의 모델 구축.
- 사전학습시 언어에 대한 일반적 지식과 task에 대한 인지 능력을 향상 시키는 것이 주목적.
- 또한 모델의 크기가 커질수록 일반화 성능도 함께 상승하는 Scaling Laws를 발견.
GPT-2
Language Models are Unsupervised Multitask Learners

GPT-2는 여러가지 task를 하나의 모델로 수행할 수 있게하기 위해 다음과 같은 과정이 추가되었다.
- 전체적인 입출력 형식은 동일하지만 task별로 구분이 가능하게 만든다.
- 이를 위해 입력에는 지시문과 문맥(context)이 함께 입력되며 모델의 출력은 정답에 해당한다.
- 즉, Pretrain 단계에서 지시문(Prompt)을 입력에 제공함으로써 현재 모델이 어떤 작업을 처리해야할지 인지시켜주는 방식을 도입한다.
- 하지만 pretrain만으로 모든 task에 최적화할 수는 없었기 때문에 필요에 따라 fine-tuning을 하기도 한다.
GPT-3
Language Models are Few-Shot Learners
GPT-3에서는 In-Context Learning이라는 개념이 소개되었는데, 여러 task들을 수행하기 위한 데이터셋, fine-tuning이 필요하지 않고, 입력으로 몇 가지 예제를 제공하는 것만으로 성능이 향상될 수 있다고 한다.
즉, 사용자가 입력한 내용에서 맥락적 의미(in-context)를 모델이 이해(learning)하고 답변을 생성할 수 있다는 것이다.
이 때 사용자가 입력한 내용에는 예제가 적용될 수 있는데 이를 shot이라고 하며 하나의 예제는 One-shot, 여러 개의 예제는 Few-shot, 예제가 없는 경우를 Zero-shot이라고 한다.
- 예제가 적용되는 경우 labeled 데이터의 수가 극소량만 있으면 된다.
- 다만 task별로 예제가 필요하며 fine-tuning 보다 최고 성능이 낮다.
- zero shot의 경우 예제가 입력에 포함되지 않기 때문에 굉장히 효율적이고 일반화 성능을 평가하기에 좋지만 그만큼 성능은 더 낮아질 수 있다.
한계점
이러한 발전에도 불구하고 여러 약점들이 존재한다.
- 같은 단어가 반복적으로 생성되거나 답변의 길이가 길어지면 일관성을 잃어버린다. 또한, 입력에 대한 응답이 부적절한 경우도 발생한다.
- 모델의 규모가 커질수록 성능은 향상되지만 규모가 굉장히 크기 때문에 추론시 비용이 너무 크다.
4.BART
4-1.개요
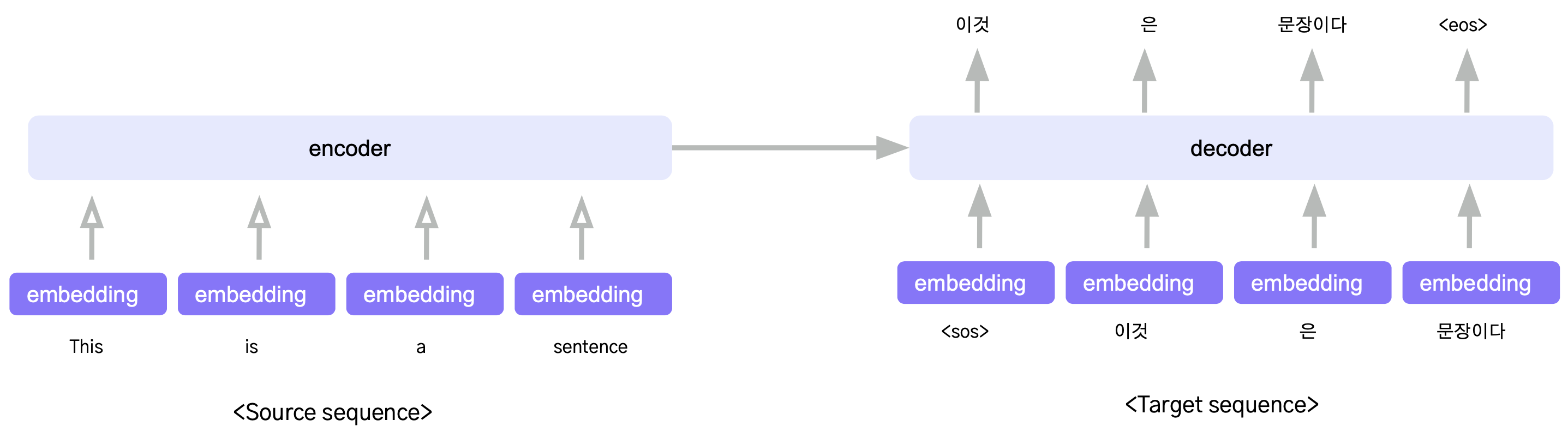
- Bart는 Transfomer와 동일한 Encoder-Decoder 구조.
- encoder는 입력 source 시퀀스를 압축하는 역할. (자연어 이해, NLU)
- decoder는 압축된 context 벡터를 입력 받아서 target 문장을 생성.(자연어 생성, NLG)
- sequence to sequence –> source와 target의 속성이 다르고 이들을 변환하는 요약, 번역과 같은 작업에 효과적이다.
4-2.Noised Pretrain
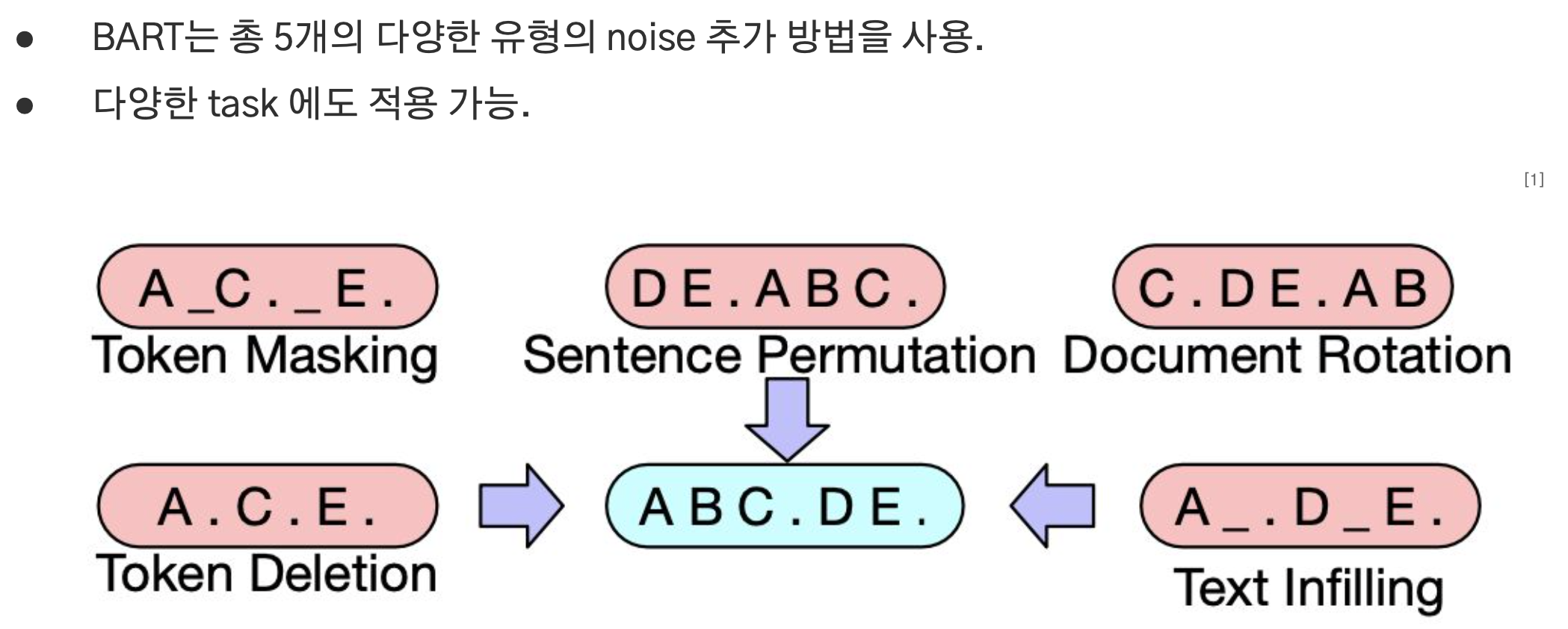
BART의 사전학습 단계에서는 원본 문장에 5개의 다양한 노이즈를 임의로 적용해 손상시키고 이를 복원시키는 방식으로 학습된다.
Token Masking
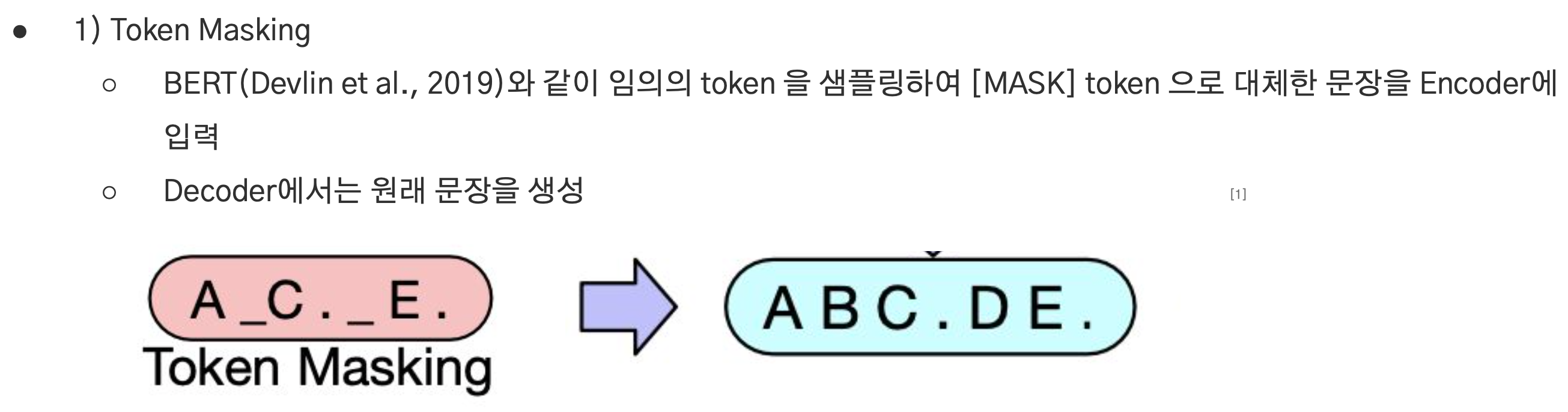
- Bert에서 적용된 것과 동일한 방식으로 임의의 토큰을 샘플링하여 MASK 토큰으로 대체한 문장을 Encoder에 입력한다.
- Decoder에서는 원래 문장을 생성.
Token Deletion
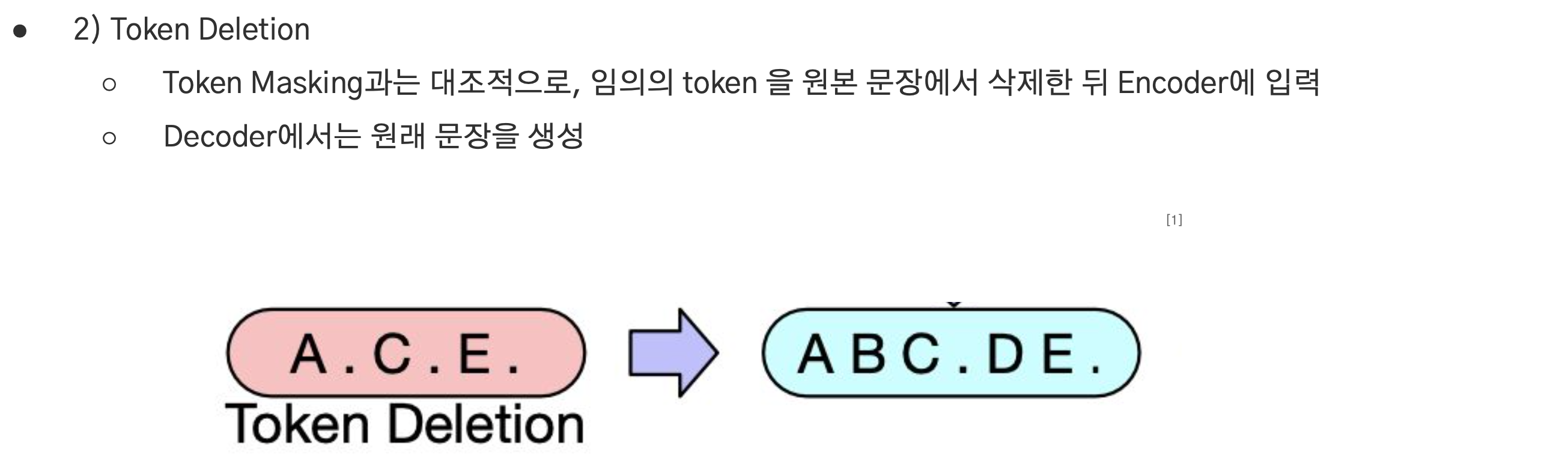
- 임의의 토큰을 삭제하고 Encoder에 입력.
- Decoder는 원래 문장을 생성.
Token Infilling
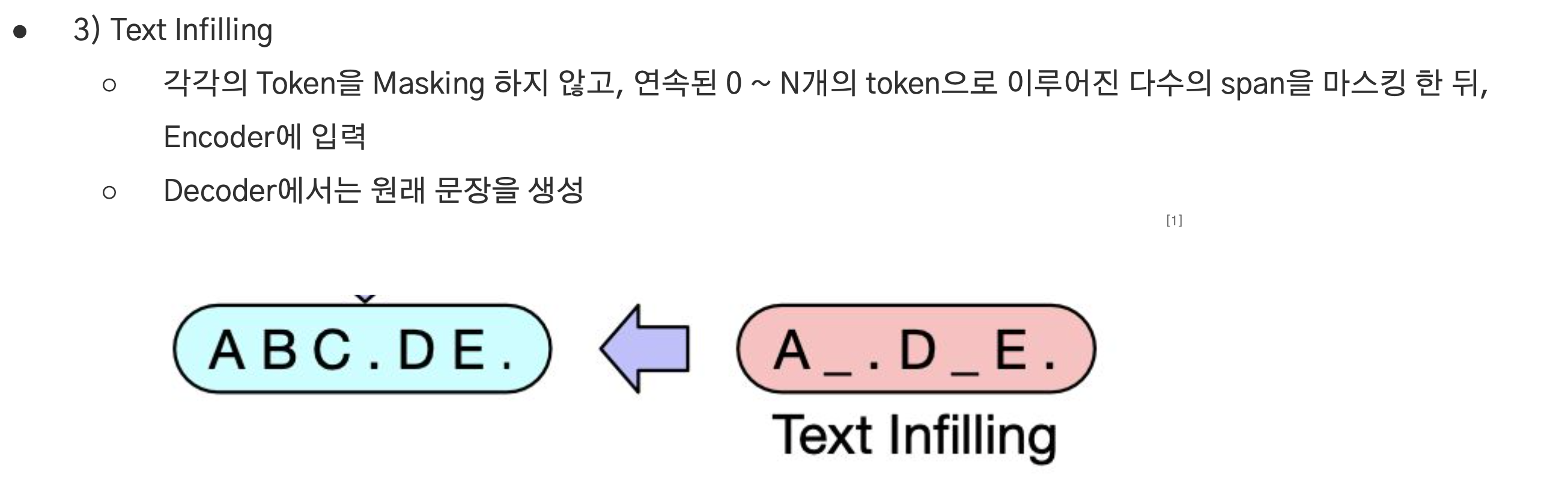
- 토큰을 마스킹하지 않고 연속된 0~N개의 토큰으로 이루어진 다수의 span을 마스킹하고 encoder에 입력.
- “나는 오늘 도서관에 가서 책을 읽을 것이다.” –> “나는 오늘 MASK에 가서 MASK을 읽을 것이다.”
- Decoder에서는 원래 문장을 생성.
Sentence Permutation
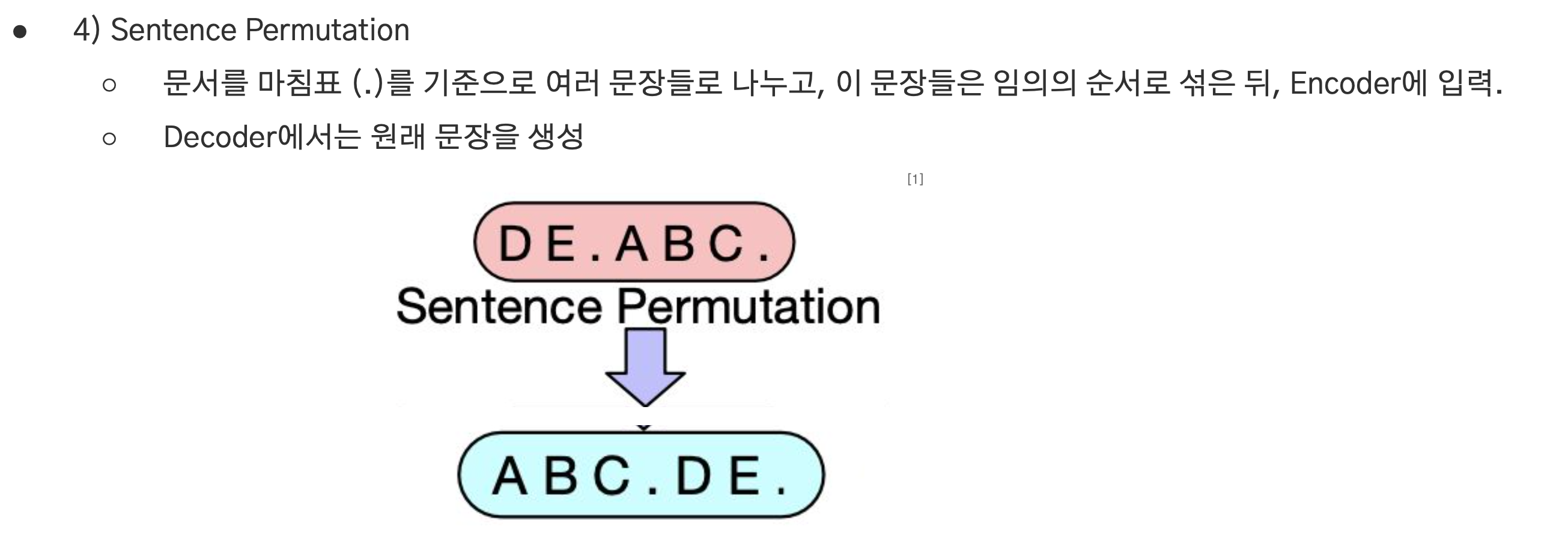
- 문서를 마침표 기준으로 분할하고 순서를 섞은 뒤 encoder에 입력.
- Decoder에서는 원래 문장을 생성.
Document Rotation
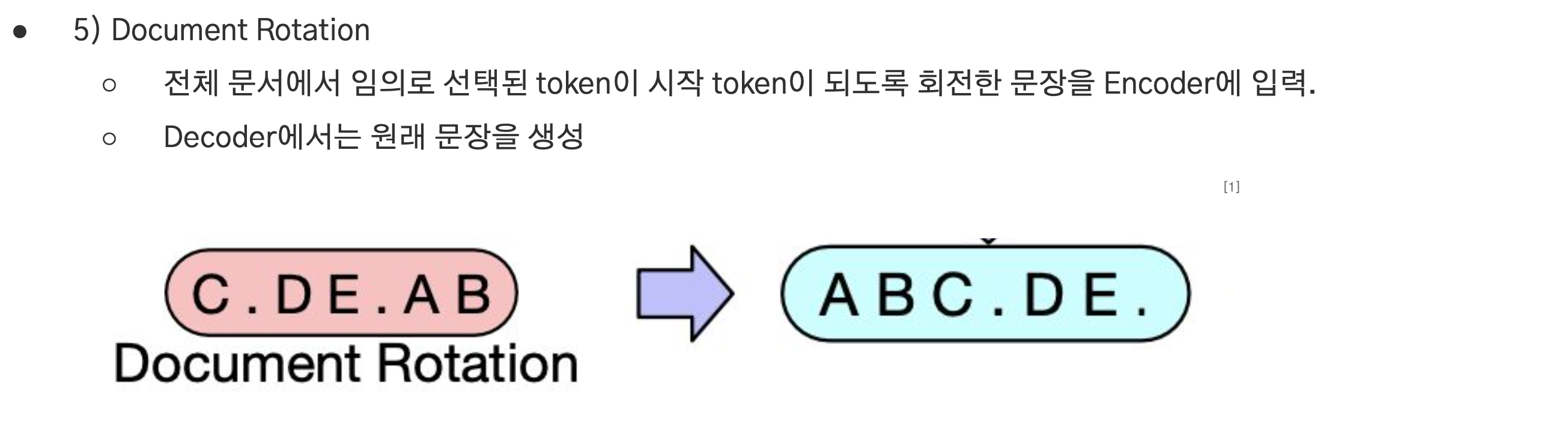
- 전체 문서에서 임의로 선택된 token이 시작 token이 되도록 회전한 문장을 encoder에 입력.
- Decoder에서는 원래 문장을 생성.
4-3.Fine Tuning
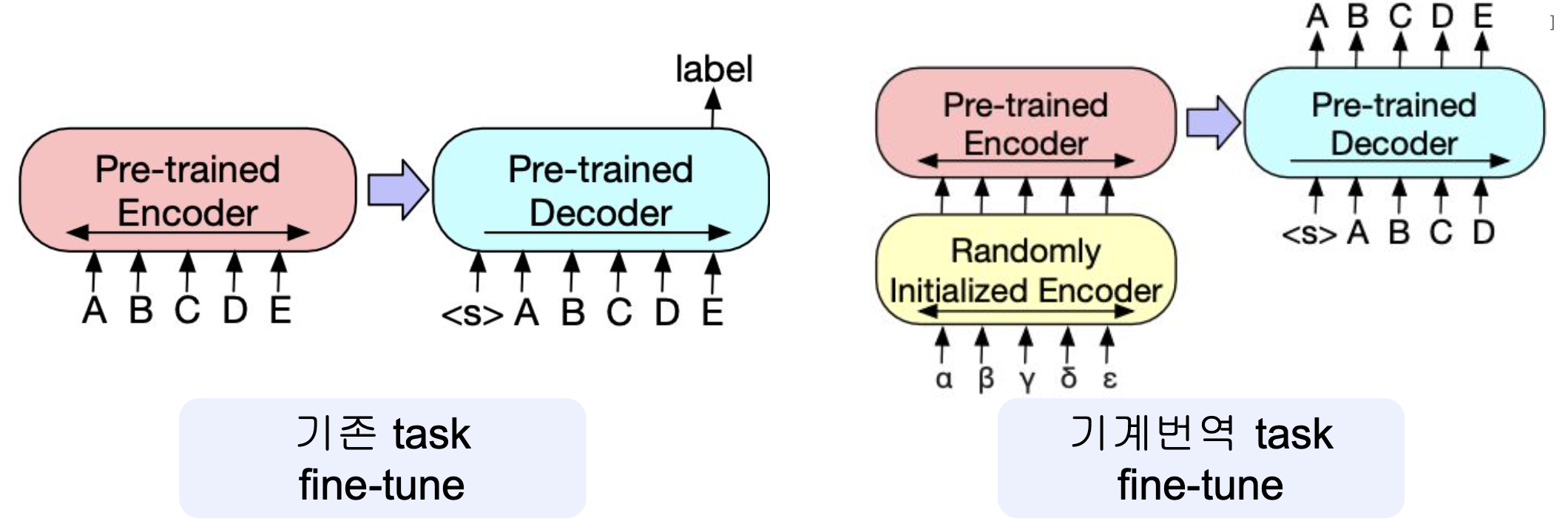
- Source 문장을 Encoder에 넣고 Decoder가 target 문장을 생성하는 방식으로 fine-tuning 진행.
- 번역이나 요약 같은 생성 작업에 효과적.
- 특히 번역에서는 pretrain 하지 않은 언어도 번역할 수 있도록 Randomly Initialized Encoder를 추가하는 새로운 방식 제시.
댓글남기기