Large Language Models
LLM에 대해 알아보자.
1.언어모델의 정의
- 주어진 텍스트의 연속된 단어들 간의 확률 분포를 학습하여 새로운 텍스트 생성, 문장 완성, 문맥 이해 등을 수행하는 모델이다.
- 언어를 이루는 구성 요소(글자, 형태소, 단어, 단어열(문장), 문단 등등)에 확률값을 부여하고 이를 바탕으로 다음 구성 요소를 예측하거나 생성하는 모델.
- 학습을 통해 문맥을 이해하고 자연어를 컴퓨터가 이해할 수 있는 지식표현 체계로 번역하는 역할을 언어 모델이 담당한다.
2.사전학습 방식의 문제
사전학습 방식 기반 언어 모델은 언어에 대한 이해를 학습하여 문맥 기반 임베딩 및 학습이 가능해 여러 가지 downstream task에서 성능 향상이 이루어졌다.
하지만 이러한 방식에도 단점 및 한계가 존재한다.
- finetuning을 위한 labeled dataset이 필요하고 downstream task별로 모델이 필요하다.
- pretrain 모델은 규모가 크기 때문에 계산 비용이 비싸다.
- 대규모 코퍼스가 필요한데 편향 및 윤리적인 문제를 어떻게 필터링 할 것인가
- finetuning을 하고 나면 사전학습 단계에서 가지고 있던 지식 대부분이 사라지게 된다.
- 사람에 따라 선호하는 결과 형태가 있으나, 이를 반영하기 어렵다.(구체적으로 설명해줘, 답만 알려줘)
- 사전학습 당시 사용했던 데이터로 지식이 확장되지 못한다. 따라서 변화하는 지식을 습득하기 위해 매번 새로 사전학습을 해야한다.(Continual Learning)
3.Large Language Models
대규모 언어모델은 이름 그대로 막대한 양의 파라미터를 가진 언어모델을 말한다. 현재 트랜드를 주도하는 기술 중 하나인데 왜 이렇게까지 뜨거운 것일까?? 그 이유를 하나씩 알아보자.
3-1.In-Context Learning
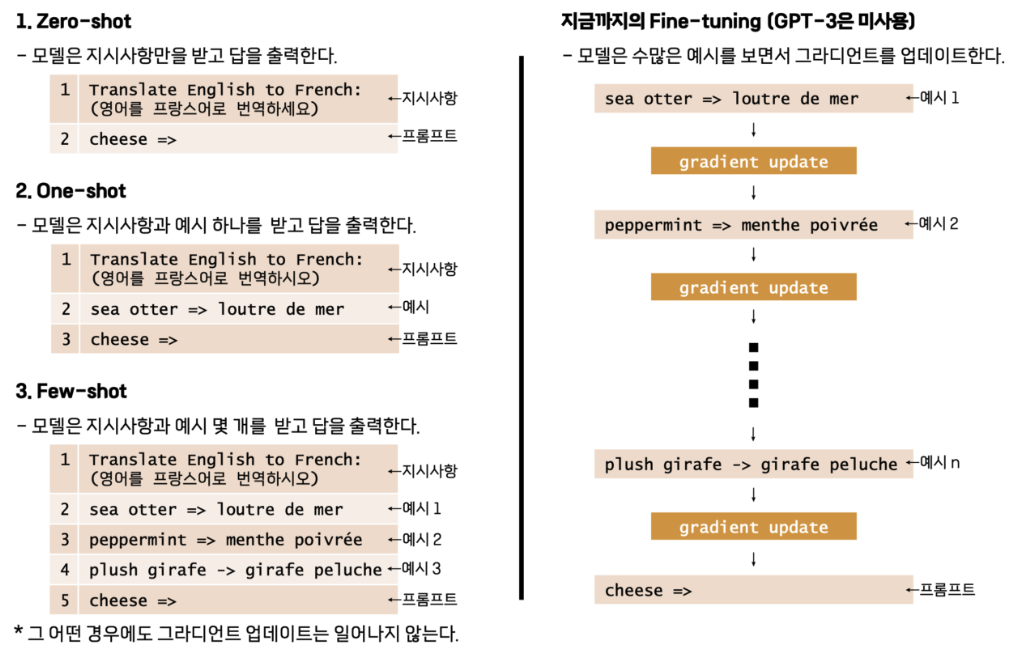
LLM은 Pretrained Model을 사용하는 것은 맞지만 finetuning과 같은 추가학습을 하지 않는다.
쉽게 말해 task에 맞는 모델 구조 변경이 필요하지 않으며, fine-tuning을 하지 않으니 weight update와 labeled data가 필요하지도 않다.
굉장히 좋아진 것 같은데 어떻게 downstream task를 수행할 수 있을지 의문이다.
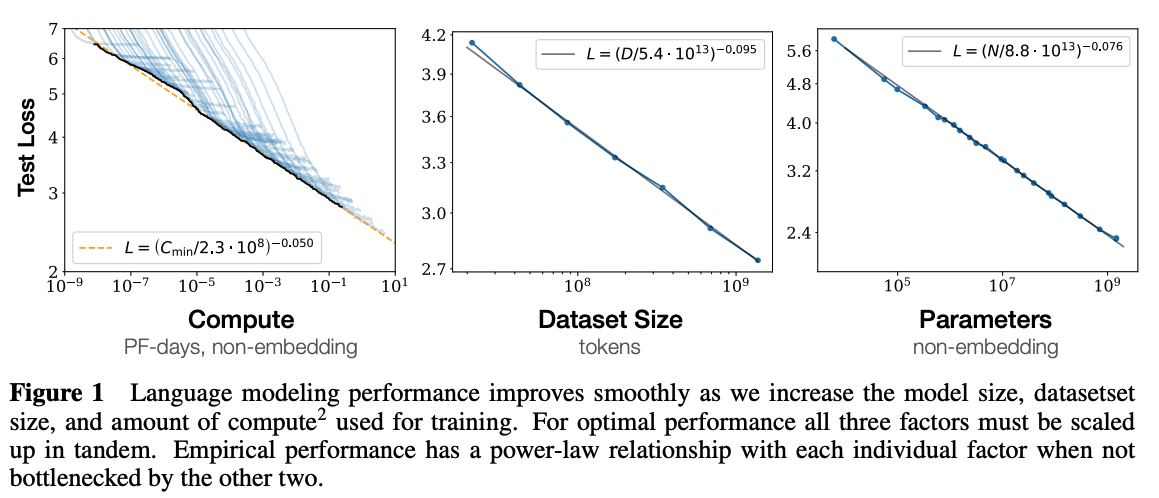
OpenAI에서는 Scaling Law라는 법칙을 발표한다. 이는 다음 세 가지가 동시에 증가하는 경우 성능이 계속해서 향상된다는 내용이다.
- Model Parameters
- Dataset Size
- Computing Resource
이를 기반으로 새로운 특징 한 가지를 발견하게 되는데, Pretrained model은 추가적인 학습 없이 사전 학습으로 구축한 능력만으로 여러 가지 task들을 해결할 수 있다는 In-Context Learning이다.
즉, 사용자가 입력한 프롬프트의 문맥을 이해하여 사전학습으로 내재된 지식(in-context)를 발현해 해당 작업을 수행하는 것이다.
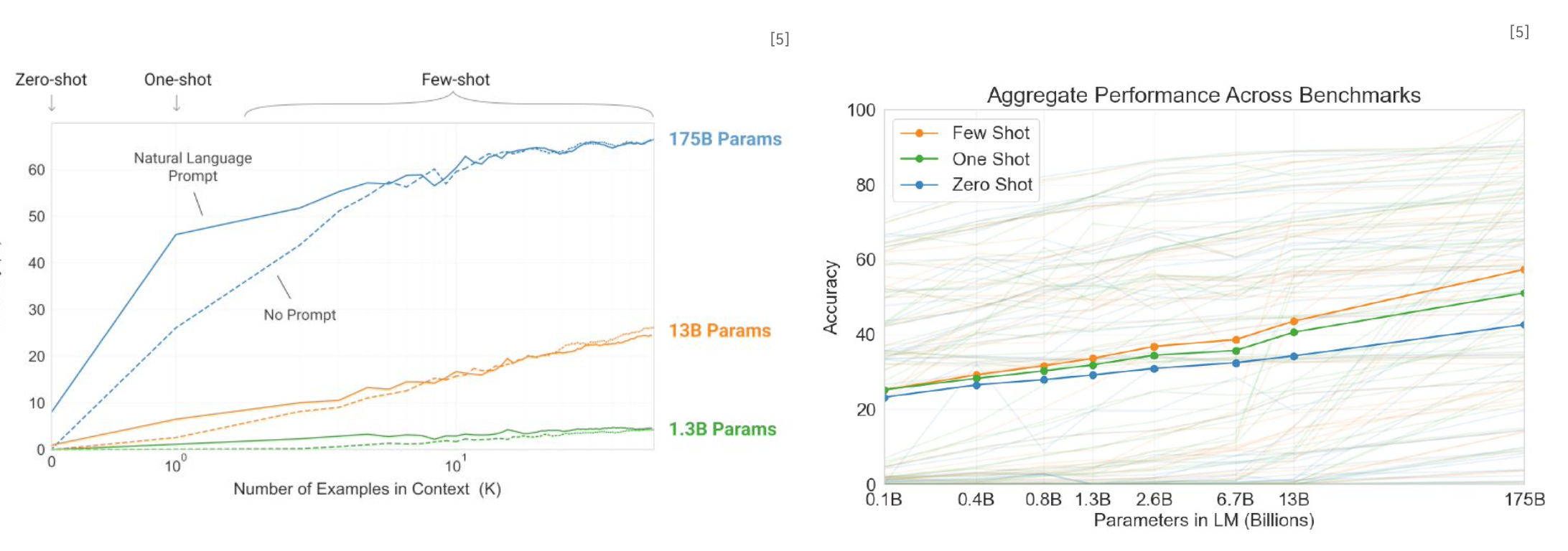
Language Models are Few-Shot Learners
또한 프롬프트에 수행할 task에 대한 예시를 포함시킬 수 있는데 하나만 포함시키면 one-shot, 여러 개 포함시키면 few-shot, 포함시키지 않으면 zero-shot이라 한다.
- 예시를 학습데이터로 본다면 fine-tuning보다 극히 적은 양으로 모델에게 downstream task를 수행하도록 할 수 있다.
- 특히 모델에 주어지는 예시의 수가 증가할수록 성능이 증가하게 된다는 것도 증명되었다.
3-2.ChatGPT
대중적으로 가장 많이 알려진 유명한 LLM은 단연 ChatGPT라고 할 수 있다.
- 기존 GPT-3는 Auto Regressive를 수행하는 모델이기 때문에 단순히 다음에 가장 적절한 단어를 생성할 뿐, 인간이 원하는 답변을 생성하기 어렵다.
- 따라서 ChatGPT는 GPT-3.5를 backbone으로 해서 사람의 선호도를 반영하는
Supervised Fine Tuning(SFT, 또는 Instruction tuning)을 수행한다. - 또한, InstructGPT처럼
Reinforcement Learning from Human Feedback(RLHF)이 적용되었다.
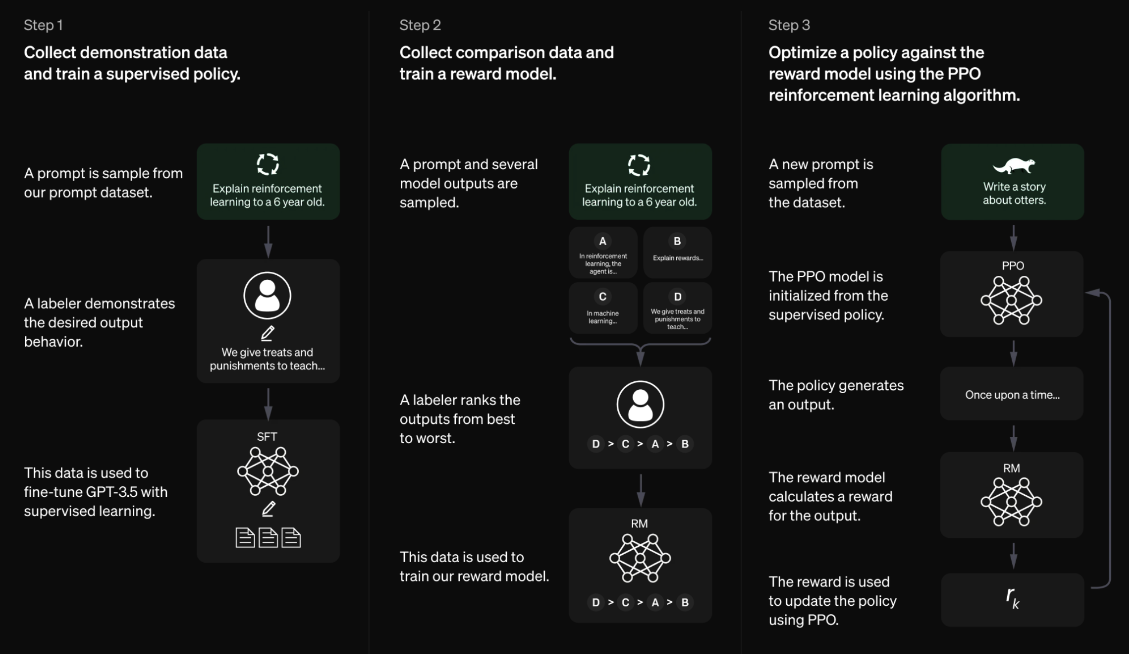
세부적인 과정을 더 자세히 살펴보자.
- 프롬프트 데이터셋과 그에 대한 결과물을 사람이 직접 labeling을 해서 labeled dataset을 구축한다. 이후 모델을 Supervised Learning하여 Instruction Tuning을 수행한다.
- SFT로 생성된 여러 가지 결과물에 대해 다시 한 번 사람이 labeling을 수행, 각각의 답변들에 랭킹을 부여한다(선호도 순위 반영). 이 데이터셋을 활용해서 Reward Model을 학습시킨다. 즉, Reward Model은 프롬프트가 주어졌을 때 사람의 선호도를 예측하는 방법을 학습한다.
- GPT와 Reward Model을 사용해 강화학습을 수행한다.
- GPT는 입력된 프롬프트를 보고 그에 대한 결과를 생성한다.
- 생성된 문장들을 Reward Model이 평가해 reward를 계산한다.
- 보상 값이 GPT에게 주어지게 되며 이에 따라 GPT는 보상을 최대화 하는 방향 즉, 사람이 가장 선호하는 답변을 생성하도록 정책을 업데이트한다.
- 이를 Proximal Policy Optimization Algorithm(PPO)라고 한다.
4.Parameter Efficient Fine Tuning(PEFT)
LLM을 Full fine-tuning하려면 굉장히 큰 컴퓨팅 자원이 필요하다. 또한, fine tuning된 모델은 사전학습 모델과 크기게 동일하기 때문에 모델 저장 및 사용 단계에서도 굉장히 비용이 크다.
따라서 기업 입장에서는 어떻게든 비용을 줄이면서 LLM을 학습 시킬 수 있는 방법들이 필요했는데 이제부터 소개할 방법들을 Parameter Efficient Fine Tuning이라 하는 방법들을 정리해본다.
- 참고로 PEFT는 LLM이 가진 파라미터들 중 극히 일부만 학습하도록 fine tuning을 한다.
- 이에 의해 연산량이 크게 감소하는 효과가 있으며 Pretrain으로 얻은 지식이 full fine-tuning으로 잃게 되는
Catastrophic Forgetting을 완화할 수 있다. - 즉, 앞으로 소개할 방법들은 데이터 양이 작거나 도메인을 벗어난 데이터를 일반화할 때 유용하다.
4-1.사전지식 : Prompt??
여러 가지 PEFT 방법들을 이해하려면 Prompt에 대해 알아야 한다.
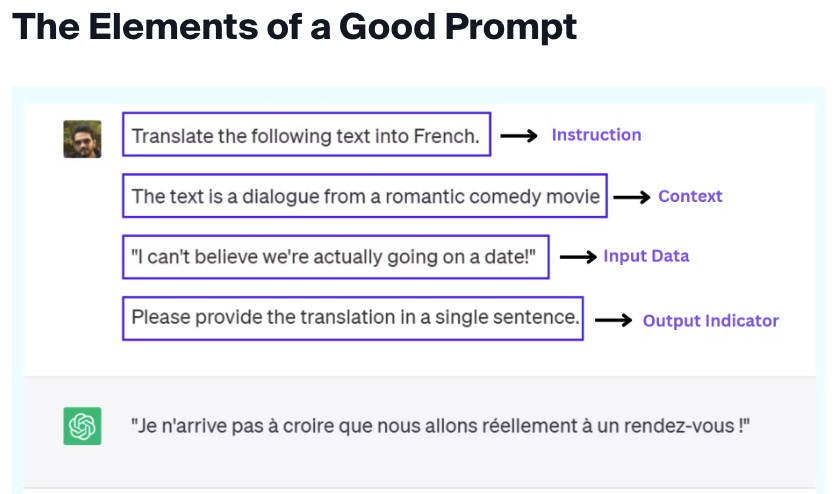
- Prompt : LLM으로부터 사용자가 원하는 결과를 도출하기 위한 input 또는 instruction.
- Prompt Engineering : LLM이 생성하는 결과 품질을 향상시킬 수 있는 prompt 입력 값들의 조합을 찾는 작업.
- Prompt의 구성
- Instruction : 모델이 수행하길 원하는 특정 task 또는 지시사항.(주어진 내용을 요약해라.)
- Context : 모델이 보다 더 나은 답변을 하도록 유도하는 외부정보 또는 추가내용(이 내용은 경제 뉴스 또는 기술 논문에서 발췌한 내용이다.)
- Input Data : 답을 구하고자 하는 것에 대한 입력값.(“올해 대한민국의 GDP 성장률을 2%로 예측했다….”)
- Output Indicator : 결과물의 유형 또는 형식.
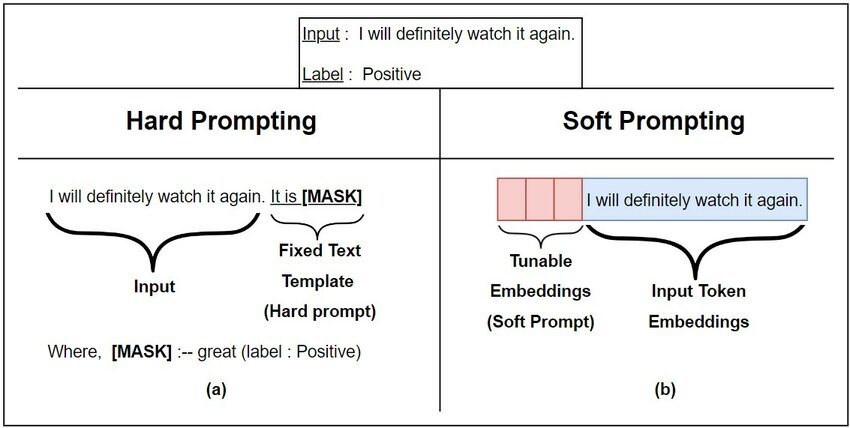
- 사람이 작성하는 텍스트 형태의 프롬프트 : Discrete 또는 Hard Prompt.
- 반대로 사람이 이해할 수 없는 형태의 프롬프트 : Continuous 또는 Soft Prompt.
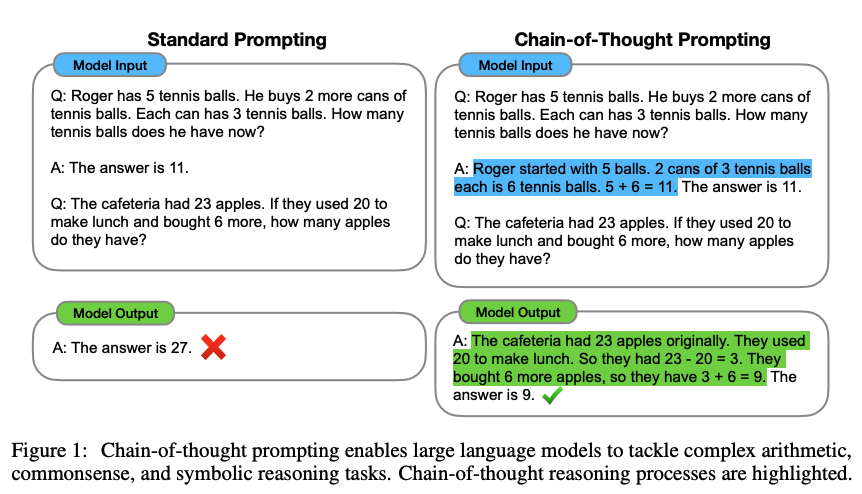
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
또한 Prompt를 구성하는 방법 중 하나로 Chain of Thought(COT)가 있는데 이는 인간의 사고방식처럼 추론 과정(흐름)을 프롬프트에 명시하여 답변에 도달하는 과정을 학습시키는 것을 목적으로 한다.
4-2.Prefix Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation
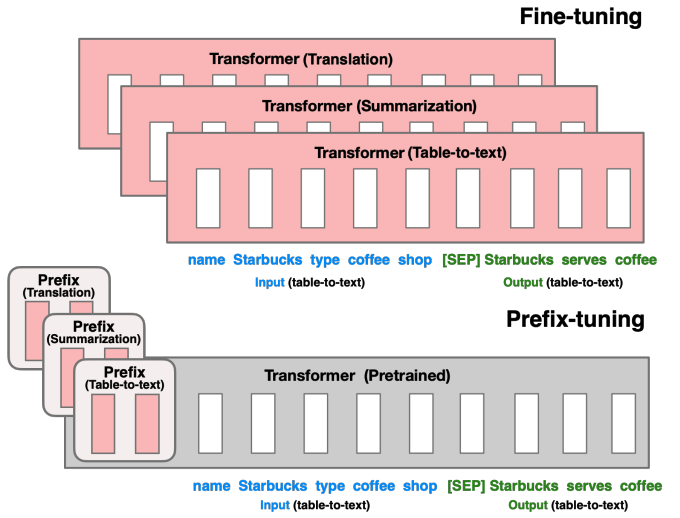
이 방법은 연속적인 task 특화 벡터를 활용해 언어모델을 최적화하는 방법이다.
- 모델은 전체 고정(feeze)하고 각 layer의 input 앞에 task-specific vector를 추가해 tuning한다.(각 층마다 별도의 학습 가능한 벡터를 추가)
- 즉, 학습시 task specific vector에 대한 gradient가 발생되며 해당 벡터만 학습된다.
- 전체 모델을 fine-tuning하는 것보다 훨씬 작은 비용을 필요로 한다.
4-3.Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
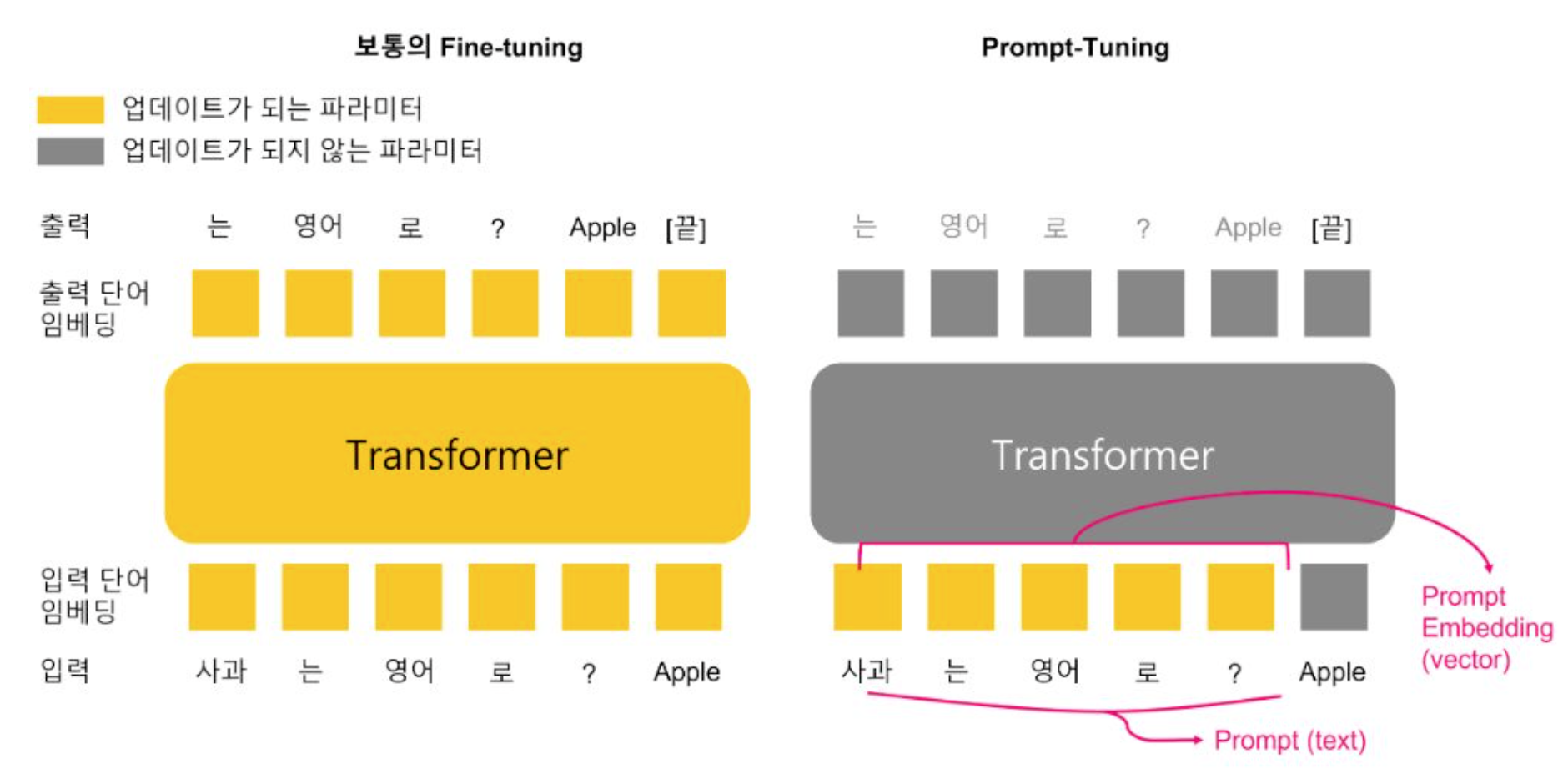
- Prefix Tuning처럼 전체 파라미터는 고정하고 입력 프롬프트 임베딩만 학습하는 방법.
- 사용자가 입력하는 프롬프트(텍스트) 앞에 학습 가능한 임베딩 벡터를 추가하고 해당 부분만 학습한다.
- 해당 벡터가 task-specific한 정보를 담도록 학습되게 된다.
4-4.P-Tuning
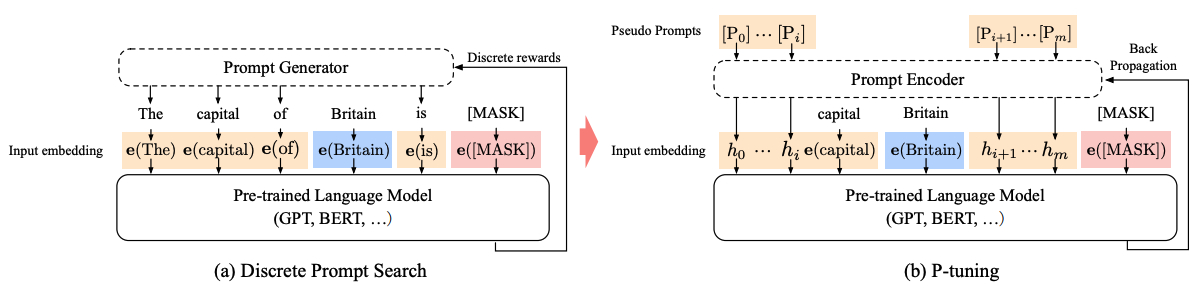
P-Tuning은 PLM의 전체 weight를 fine-tuning하지 않고 continuous promt embeddings만 tuning하는 방법이다.
이는 Prompt tuning과 유사해보이지만 LM의 입력부에 prompt encoder(Bi-LSTM)를 두어 나온 출력 값을 prompt의 token embedding으로 사용한다.
즉, prompt-encoder는 task별로 tokens를 만들어내게 되는데 이를 anchor-tokens이라 한다.
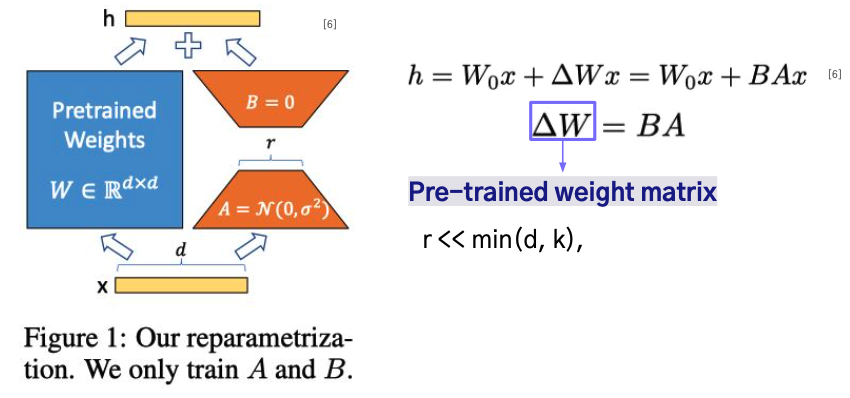
4-5.LoRA
LoRA: Low-Rank Adaptation of Large Language Models
LoRA는 pre-trained weight를 고정한 상태로 유지하며 linear layer 변화에 대한 rank decomposition metrices를 최적화하는 방식이다.
쉽게 말해 LLM은 고정시키고 Low rank feed-forward adapter layer를 기존 output과 더하는 방식이다.
GPT-3의 경우 175B의 파라미터 중 0.01%의 파라미터만 사용하므로 굉장히 높은 효율성을 보여주며 rank를 작은 값으로 설정해도 성능이 유지될 수 있다.
4-6.QLoRA
QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA는 Quantization을 LoRA에 도입하여 효율성을 더욱 높힌 방법이다.
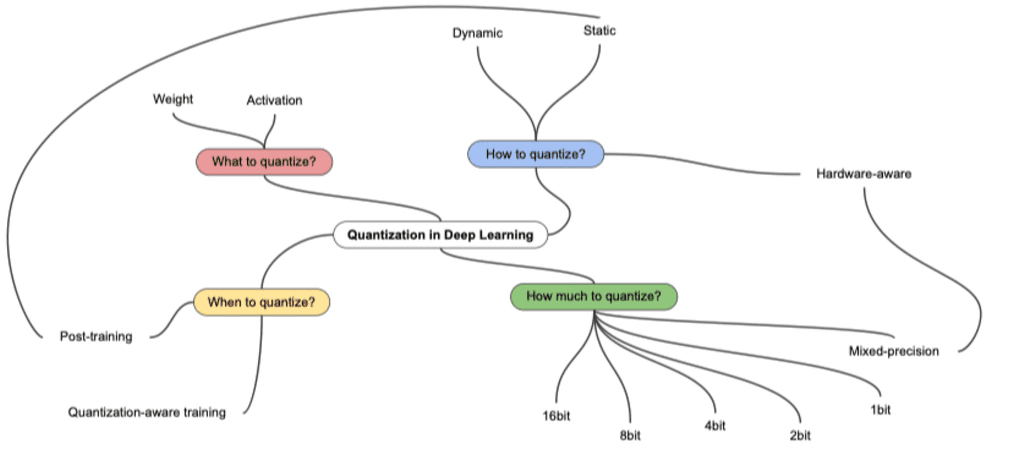
- 모델의 파라미터를 lower bit로 표현함으로써 계산과 메모리 속도를 높히는 경량화 기법이다.
- 보통 Quantization은 Training Time을 줄이는 것보다 inference time을 줄이는 것이 주목적이다.
- 보통 32비트 부동소수점 연산을 16비트 부동소수점 또는 8비트 정수로 변환하는 방식을 사용한다.
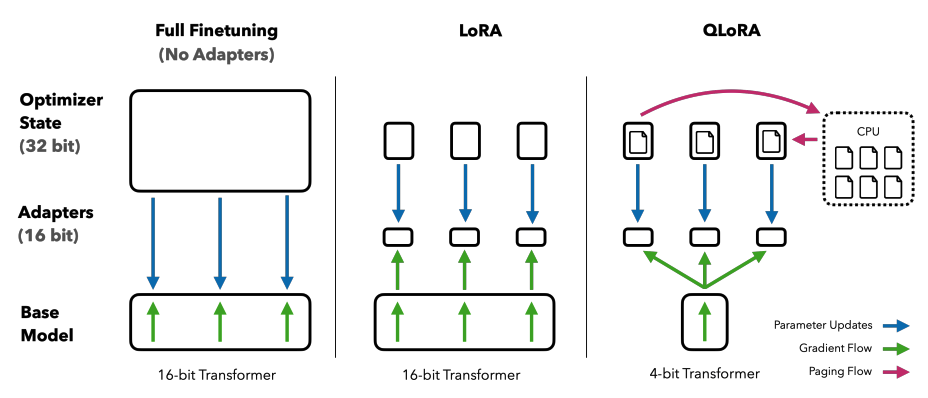
사전학습 모델을 4-bit로 양자화하게 되는데 16-bit fine-tuning 성능을 유지하면서 단일 48GB GPU에서 650억 매개 변수 모델을 fine tuning할 수 있다.
4-7.IA3
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning

LoRA의 경우 hidden state에 새로운 값을 더해주는 기법이지만, IA3는 Self-Attention, Cross-Attention에서의 Key, Value 값을 rescale해주는 벡터와 position-wise feed-forward network의 값에 rescale을 해주는 벡터를 추가해서 모델을 튜닝하는 기법이다.
특히 이 방법은 LoRA보다 적은 파라미터를 사용하면서 높은 성능을 낸다는 장점이 있다.
4-8.LLaMA Adapter
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
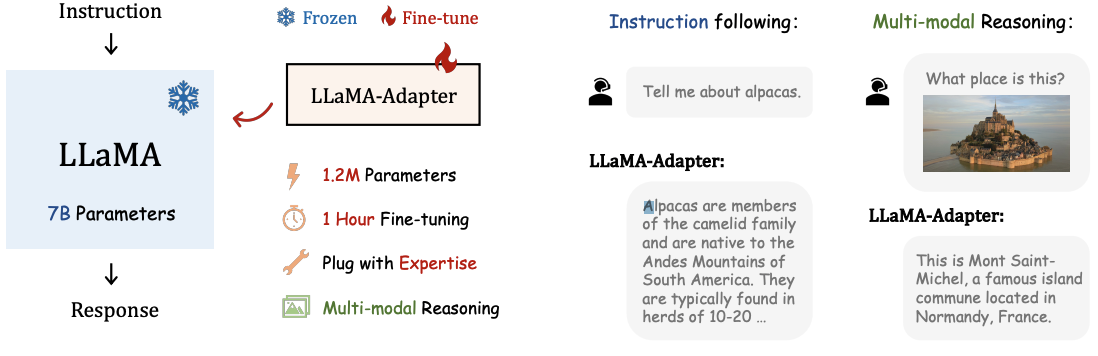
LLama 모델을 instruction 모델로 미세 조정할 때 효율적으로 하기 위한 방법이다. 학습 가능한 프롬프트 토큰을 상위 Transformer layer의 입력 텍스트 토큰 앞에 추가해 학습한다.
1.2M개의 적은 파라미터로 각 어뎁터를 유연하게 삽입하여 다양한 지식을 부여할 수 있으며, Multi-Modal conditioning이 가능하다.
댓글남기기