Attention Mechanism, Transformer
Attention과 Transformer
1.Seq2Se2
Attention에 대해 알아보기 전에 Sequence to Sequence에 대해 먼저 알아보려한다.
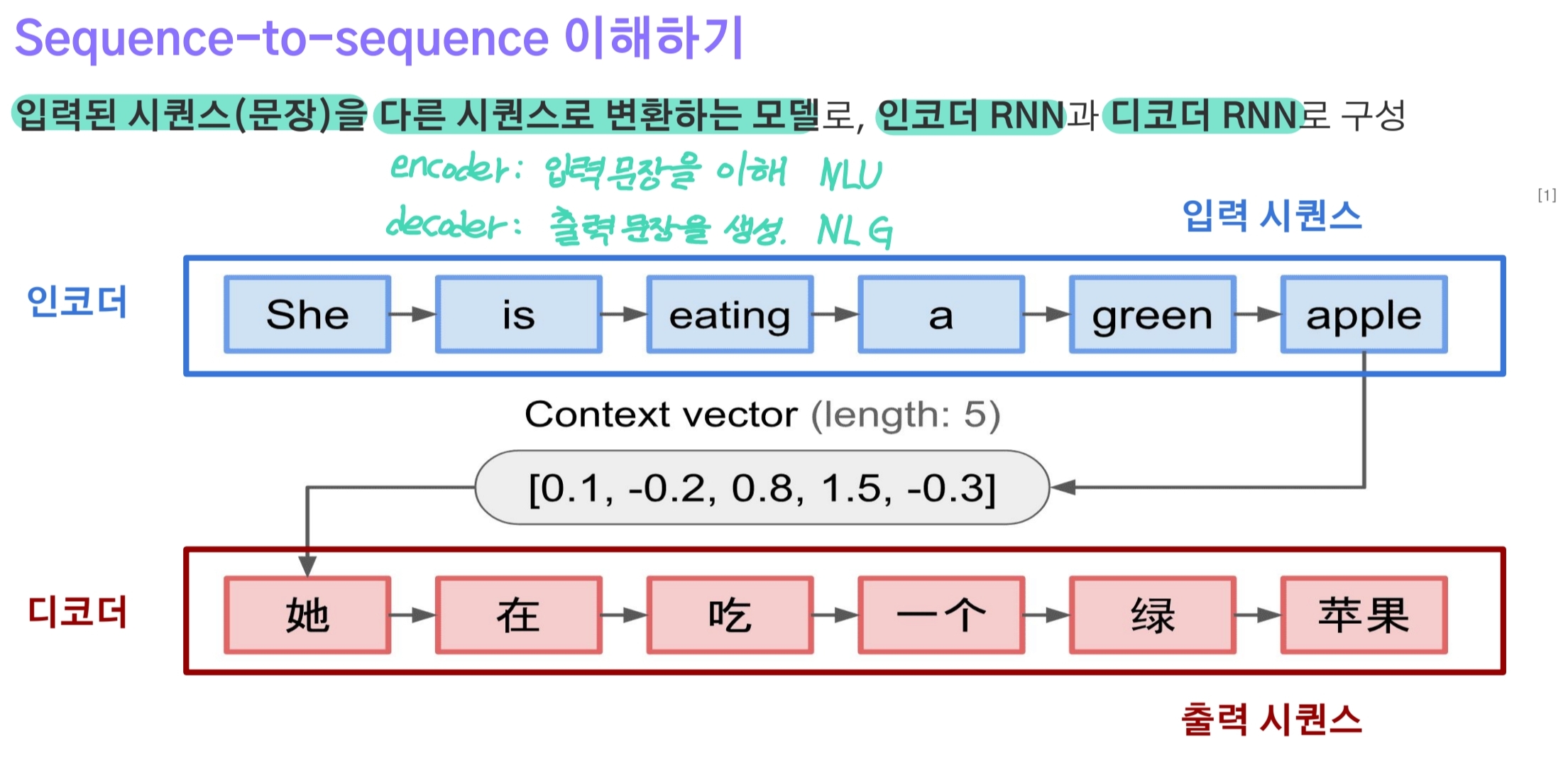
seq2seq는 기계번역 문제를 풀기 위해 개발된 Encoder-Decoder 구조이다.
- Encoder는 소스 시퀀스(source language)를 입력 받아 고정된 차원의 context vector로 압축한다.(NLU)
- 이 때 context vector는 마지막 시점 t의 hidden state($ h_t $)이다.
- Decoder는 context vector를 initial hidden state로, 최초 입력 $x_0$로 SOS(또는 BOS) 토큰을 입력 받는다.
- 입력을 받아서 타겟 시퀀스(target language)를 생성하는데(NLG) 한 번의 timestep t마다 하나의 단어를 생성하는 방식을 반복해 문장을 만들어낸다.
- 즉, target vocab에 있는 단어들 중 어떤 것이 현재 적합한 단어를 가장 높은 확률로 얻게 되고, 이를 다음 단계 단어 예측을 위한 입력으로 사용하는 Auto-Regressive 방식으로 동작한다.
2.Attention
2-1.정의
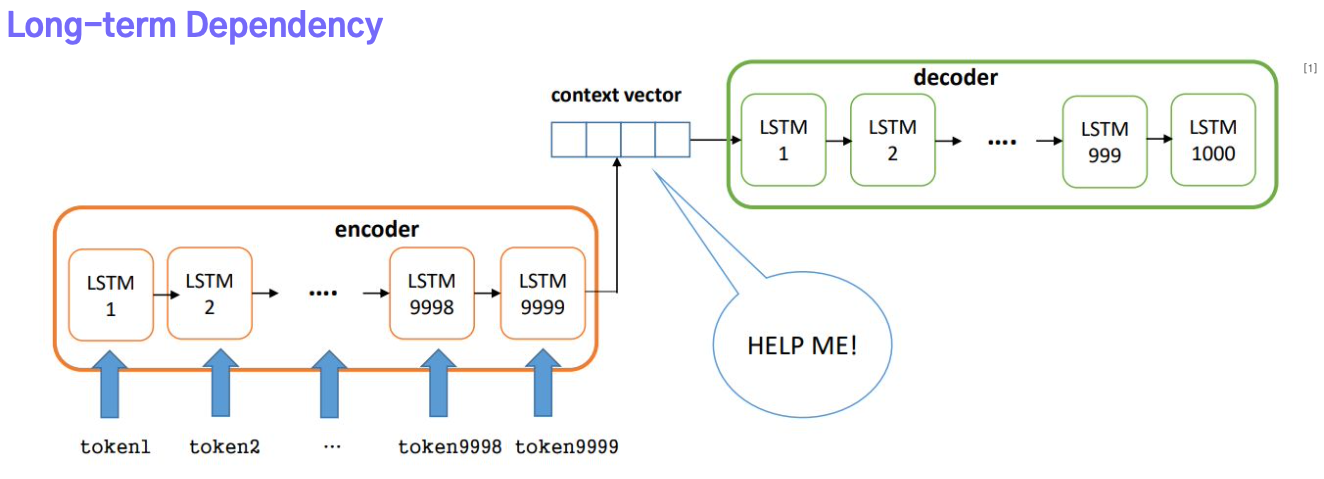
초기 Attention 논문에서는 기존 seq2seq가 가진 문제점들을 제시한다.
- Encoder에서 시간별로 계산한 hidden state 중 마지막 $h_t$만 context vector로 사용된다.
- 이는 시퀀스의 길이가 길어질수록 고정된 크기의 벡터에 시퀀스 데이터를 압축하려다보니 정보 손실, LongTerm Dependency로 인해 초반부 정보들이 점점 희미해진다.
Attention 메커니즘은 사람이 글을 읽을 때처럼 모든 단어들을 집중해서 읽는 것이 아니라 중요하다고 생각하는 단어에만 집중하는 방식이다.
쉽게 말해 문맥에 따라 집중해야할 단어들을 결정하고 이를 기반으로 context vector를 만들면 더 효과적인 압축이 가능해지는 것이다.
- Encoder에서 계산한 timestep별 hidden state들을 모두 decoder로 전달한다.
- Decoder는 생성을 수행하는 timestep마다 각각의 hidden state에 대한 점수를 계산, 집중할 부분을 찾고 이를 기반으로 현재 적합한 단어가 무엇인지 결정한다.
2-2.Query, Key, Value
Attention에서는 query, key, value라는 용어들이 등장한다.
- query : 내가 찾고자하는 정보. 검색어.(구글에 what is attention을 검색.)
- key : 검색 결과.(검색한 결과로 나온 모든 페이지들 -> 제목, 작성자, 내용 등등)
- value : 우리가 찾고자하는 목표값.(페이지별로 가진 실제값.)
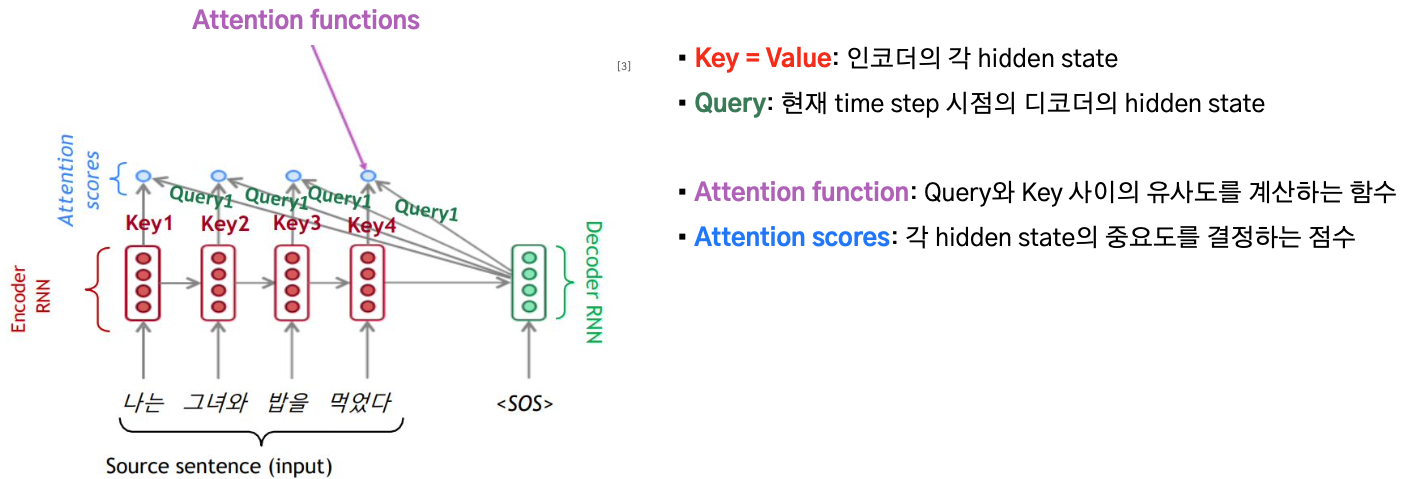
seq2seq 관점에서 query, key, value는 다음과 같다.
- key, value는 encoder에서 계산한 모든 hidden state
- query는 decoder의 현재시점 t의 hidden state
2-3.계산 과정
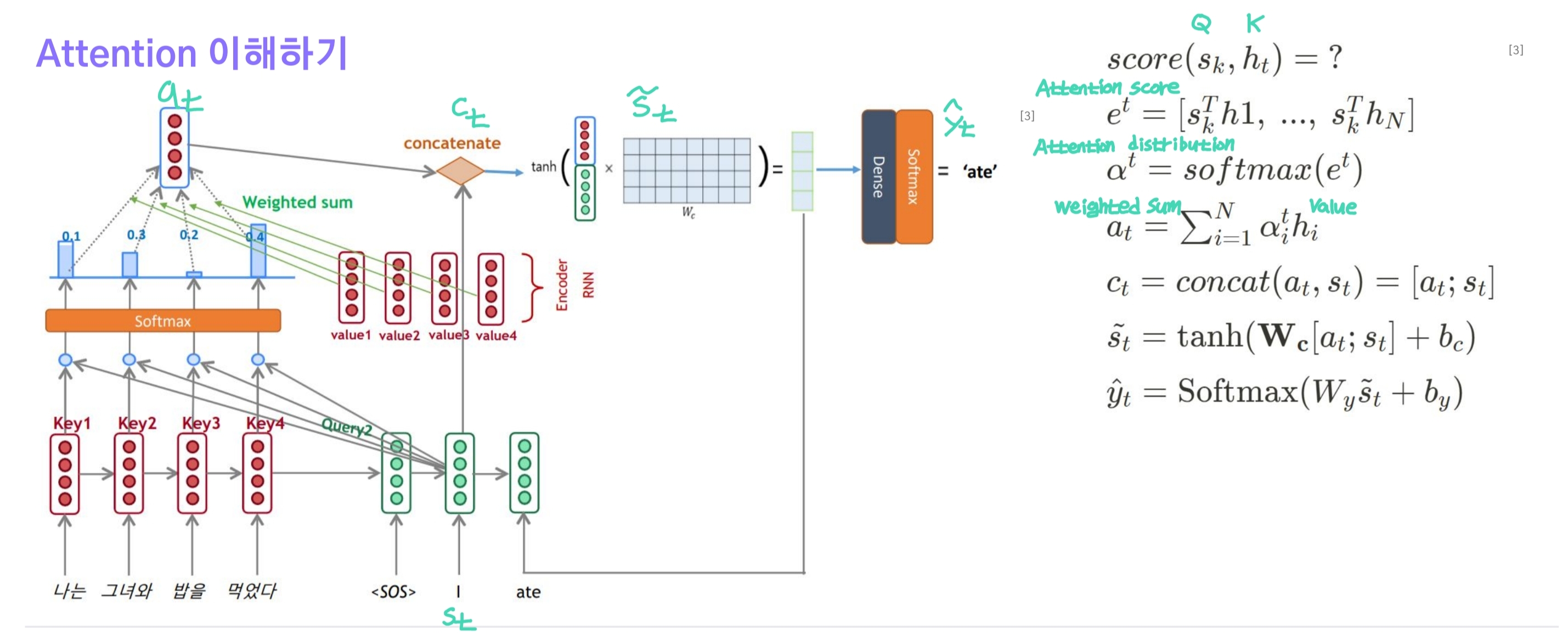
이제 전체 계산과정에 대해 정리해보자.
- $s_t$는 decoder의 특정 시점 hidden state(Query), $h_1, h_2, …, h_t$는 encdoer에서 구한 모든 hidden state(Key)이다.
- 가장 먼저 $s_t$와 $h_1, h_2, … h_t$ 각각에 대한 dot product를 수행한다. 그 결과 t개의 스칼라가 얻어지며 하나의 벡터로 볼 수 있는데 이를
Attention score라고 한다. - attention score를 softmax 함수에 입력시켜
Attention distribution을 얻는다. - attention distribution의 각 원소는 확률로써 encoder의 각 hidden state별로($h_i$, Value) Weighted Sum을 계산한다.
Attention Value - attention value와 $s_t$를 concat해서 $c_t$를 얻게 되고 이를 linear layer에 입력시켜 $ \tilde s_t$를 구한다.
- $ \tilde s_t$를 출력층에 입력시키고 sotmax 함수를 적용해 target vocab 크기의 확률 벡터를 얻는다. 여기서 가장 높은 확률이 현재시점에 가장 적합한 단어에 해당한다.
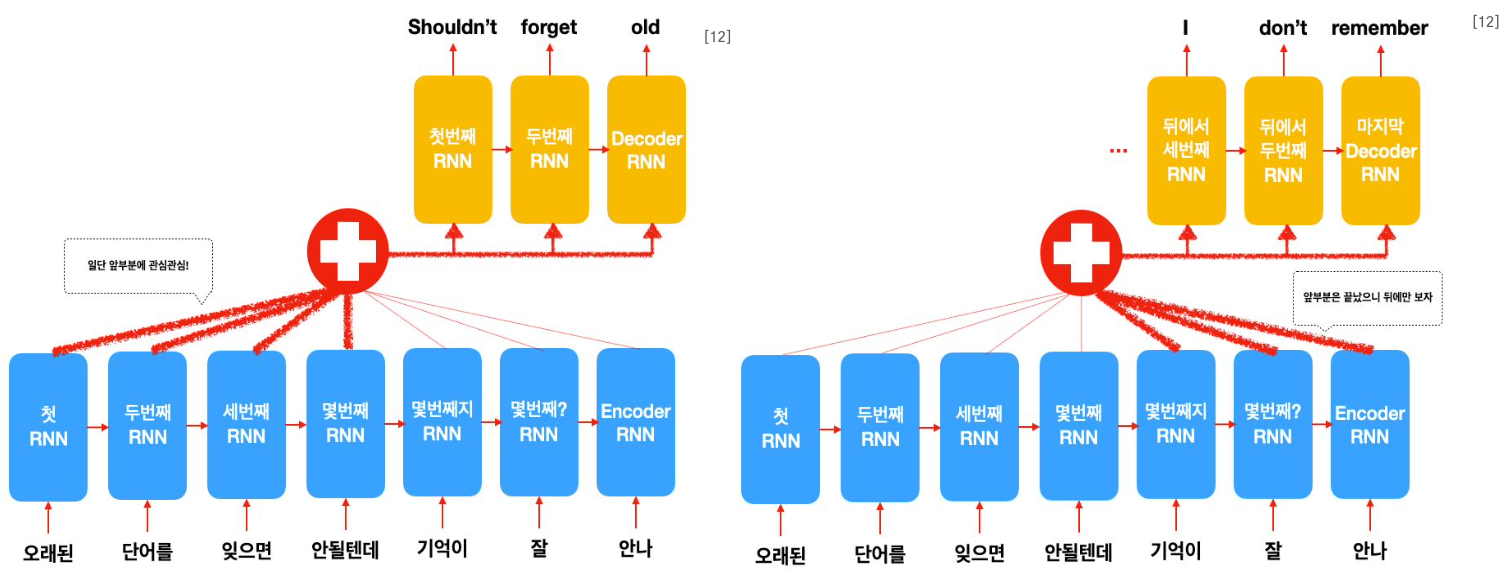
결과적으로 decoder는 생성해야하는 시점 t마다 Attention 메커니즘으로 Attention value를 계산하게 되는데, 이것이 seq2seq의 context vector와 동일한 역할을 한다. 즉, 매 시점마다 context vector를 새로 계산한다.
- 단순히 시간의 진행에 따라 단순히 입력 시퀀스를 압축하는 것이 아니라 시점별로 어느 부분이 중요한지 계산하여 context vector로 반영한다.
- 즉, attention value가 매 시점마다 새롭게 계산, 변경되므로 시점마다 적합한 단어를 예측하는 것이 가능하고 Long-Term Dependency에 강건해질 수 있다.
3.Transformer
3-1.구성 살펴보기
Transformer는 Attention is All You Need라는 제목으로 발표된 모델이다.
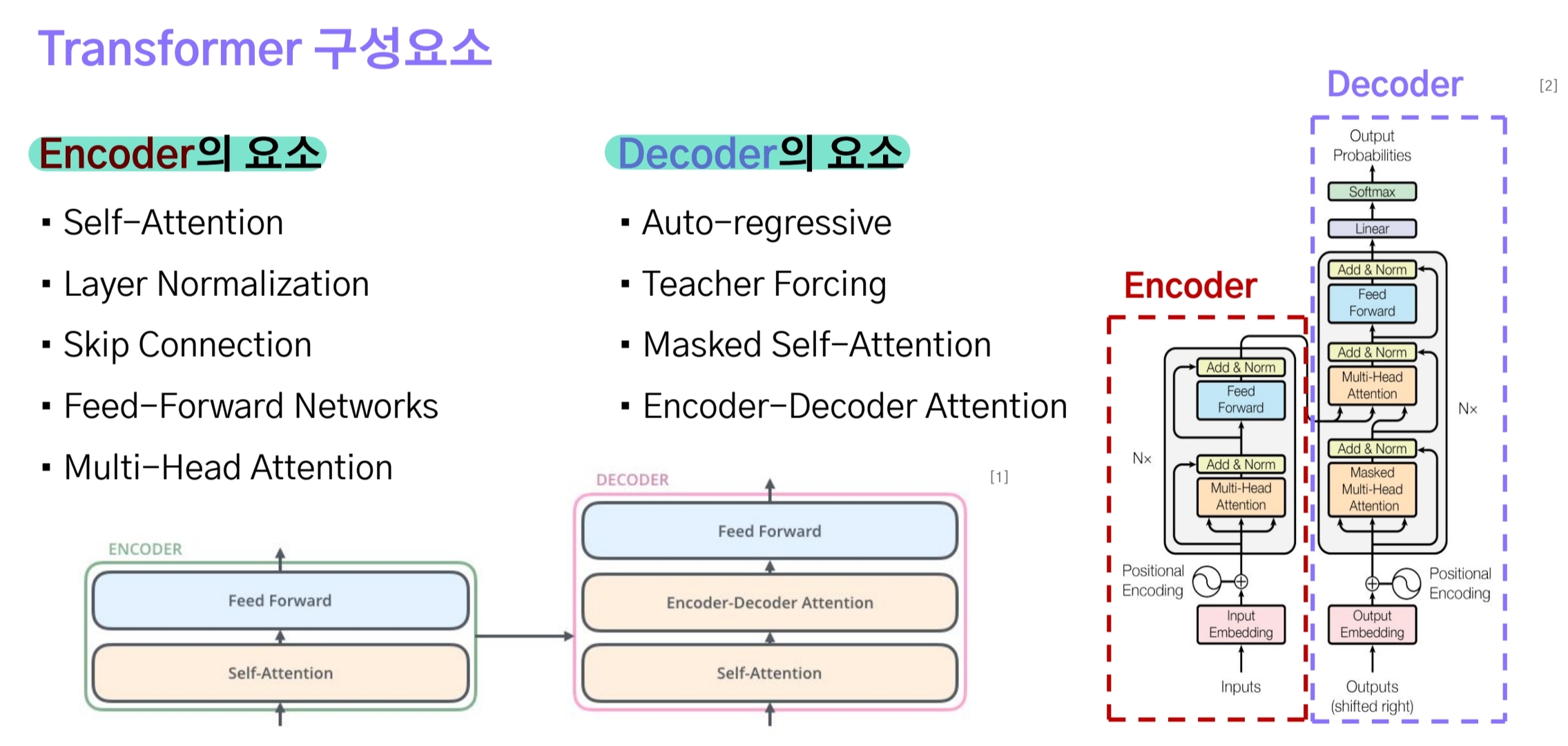
transformer 모델도 seq2seq와 같이 Encoder-Deocder 구조로 설계되어 있지만, RNN 계열의 모델은 사용하지 않고 오로지 attention과 linear(dense) layer만으로 구성된 모델이다.
이러한 구조적인 변화를 통해 현재단계의 Hidden state를 계산할 때 이전단계의 정보가 활용되지 않으므로 병렬적으로 연산이 가능해져 더 효율적이다.
3-2.Embedding + Positional Encoding
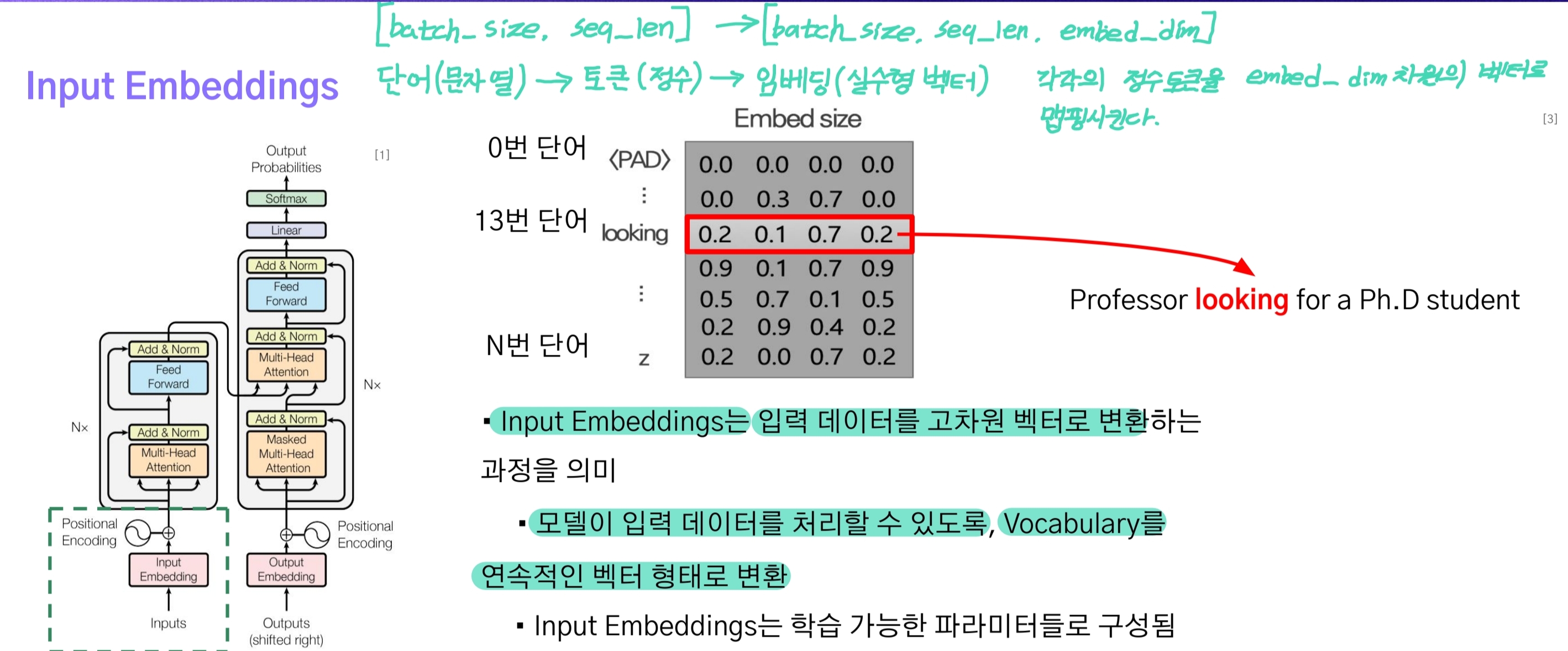
우선 입력된 시퀀스 데이터는 [batch_size, seq_len]의 형태다. 이는 nn.Embedding에 입력되며 학습을 통해 각각의 토큰은 $d_{model}$차원의 벡터로 변한다.
참고로 이는 word2vec과 같이 단어와 같은 단위 토큰들이 어느 차원의 공간내 벡터로 맵핑되는 것으로, 각각의 토큰이 벡터가 되어 [batch_size, seq_len, d_model]의 형상으로 변환된다.
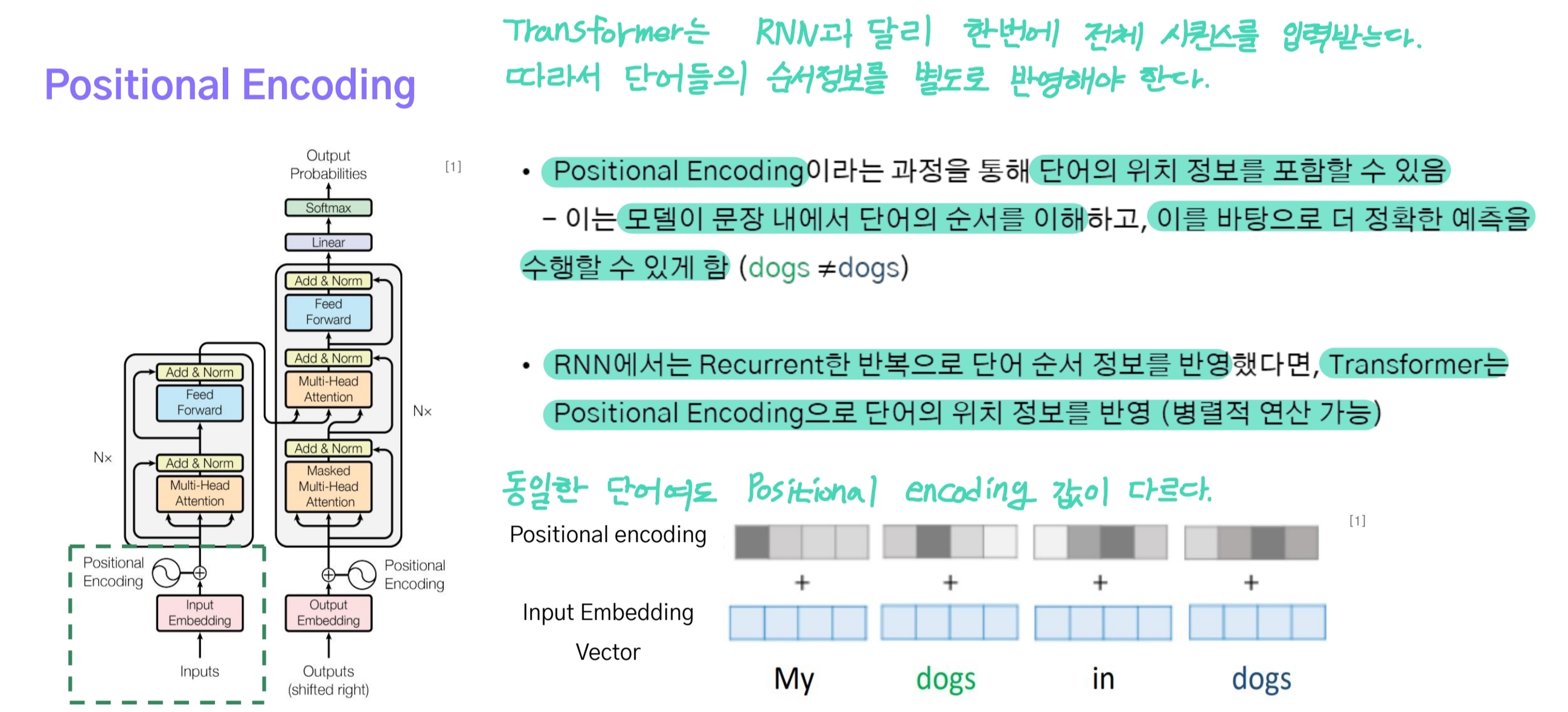
트랜스포머는 RNN 모델을 사용하지 않기 때문에 입력되는 시퀀스 데이터를 순서대로 처리할 수 없다. 즉, 각각의 토큰에 대한 순서 정보를 반영할 수 없다.
이러한 문제를 해결하기 위해 Positional Encoding이 적용되었는데 이는 각각의 토큰에 cosine, sine 함수의 주기를 사용함으로써 가까운 위치에 있는 단어들은 비슷한 값을 갖고, 멀리 떨어진 단어들은 그만큼 큰 차이를 갖게 된다.
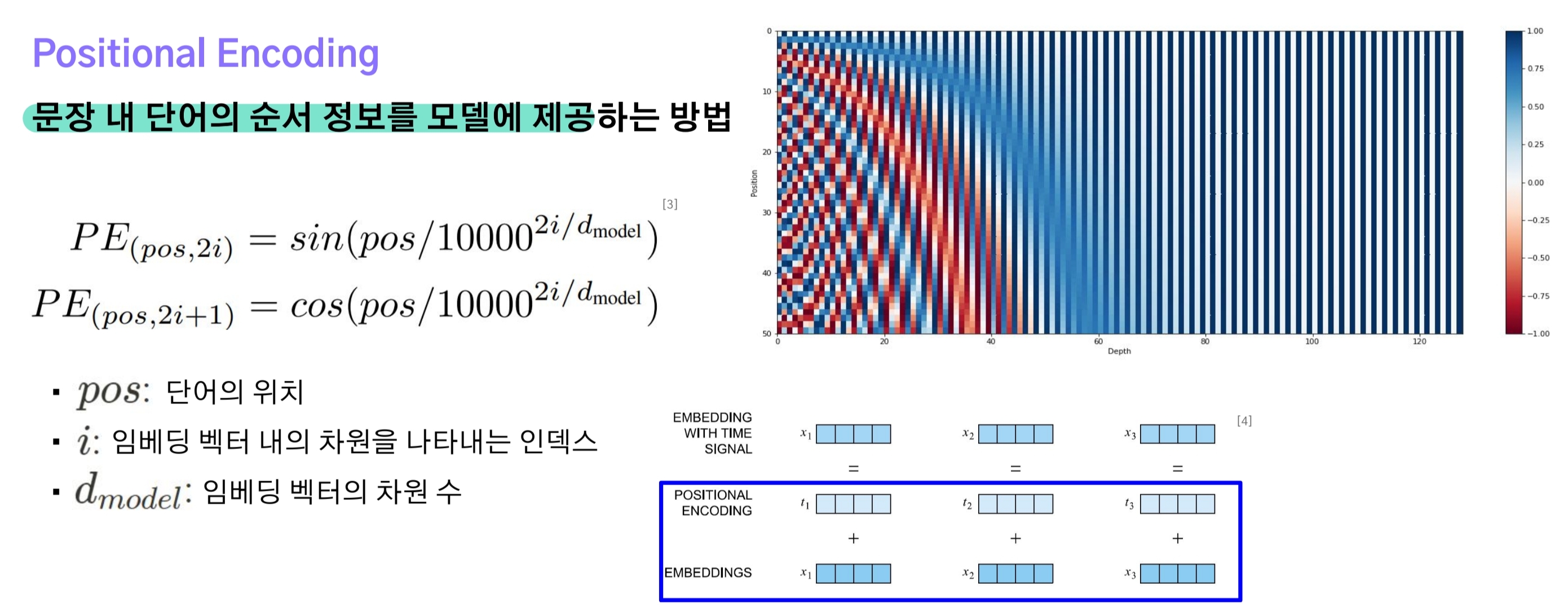
- 쉽게 말해 Positional Encoding을 사인(sin)과 코사인(cosine) 함수의 주기를 잘게 쪼개서 각 토큰의 위치에 따라 값을 할당하는 것.
- 결과적으로 문장 내 동일한 단어임에도 위치가 달라져 encoding 값은 서로 다르게 된다.
- positional encoding 벡터는 embedding 벡터에 더해지게 되므로 둘다 [batch_size, seq_len]로 형상이 같다.
3-2.Self-Attention
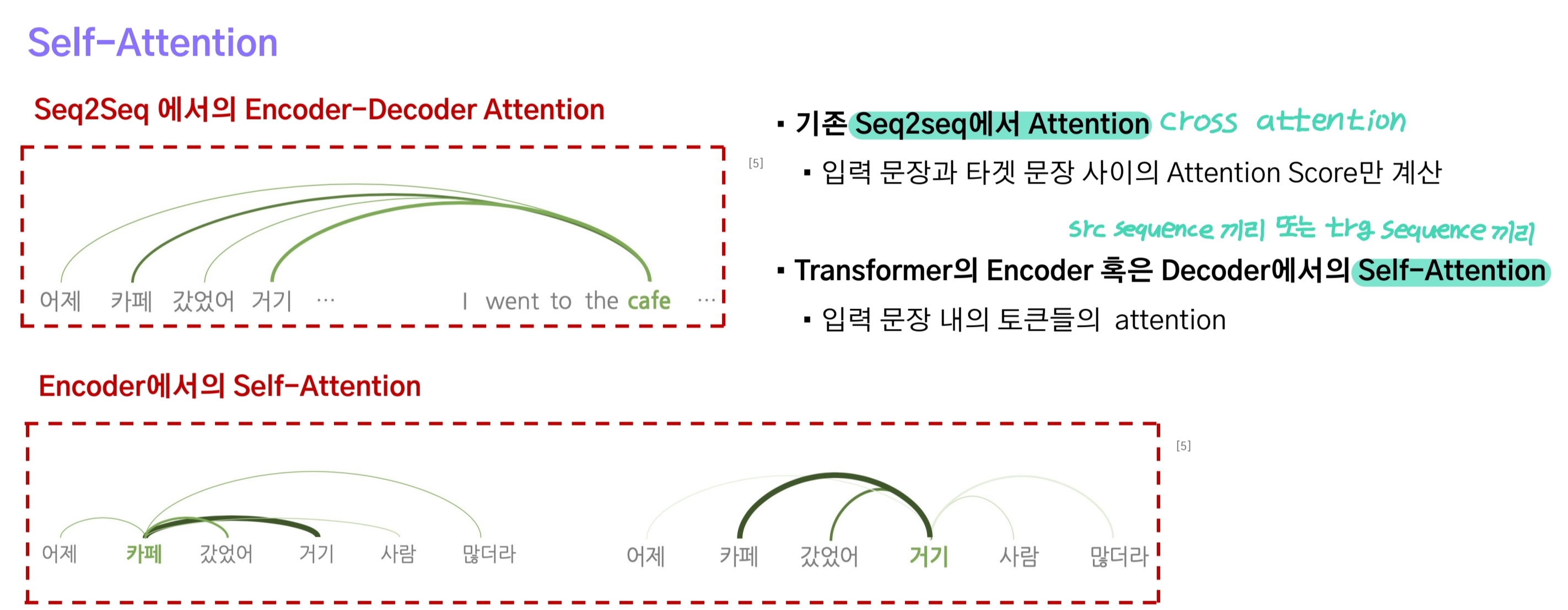
seq2seq에 적용된 Attention은 query로 decoder의 t번째 hidden state를, key와 value로는 encoder의 모든 hidden state에 해당했다.
반면에 self-attention은 query, key, value의 출처가 encoder 또는 decoder로 동일한 attention을 말한다.

The animal didn’t cross the street, because it was too tired.
위 문장에서 사람은 ‘it’이 ‘animal’에 해당함을 알 수 있지만 컴퓨터는 이를 알아내지 못한다. 따라서 Self-Attention은 현재 보는 단어(Query)와 입력 문장을 구성하는 모든 단어들(Key) 사이의 attention을 계산하여 연관성을 계산해 “it”이 “animal”임을 알 수 있게 만든다.
즉, Self-Attention은 모든 token들 사이의 연관성을 한 번의 행렬곱으로 계산하는 방식으로 병렬처리가 가능하며, 문장에 n개의 token들이 있을 경우 $n\times n$번의 연산을 수행해 모든 token들 사이의 연관성을 계산한다.
Scaled Dot-product Attention
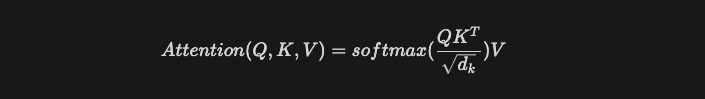
트랜스포머 모델에서 사용하는 attention은 위 수식처럼 Scaled Dot-product Attention이다.
seq2seq에서 봤던 것처럼 Query, Key, Value 벡터를 만들어야 하는데, embedding + positional Encoding [batch_size, seq_len, d_model]을 3개의 독립적인 linear layer에 입력한다.
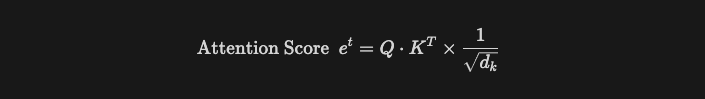
- Query는 입력 시퀀스의 토큰 하나. [batch_size, seq_len, d_k]
- Key, Value는 입력 시퀀스 전체. [batch_size, seq_len, d_k]
- Self-Attention은 입력 시퀀스의 각 단어와 전체에 대한 관계를 Dot-product로 계산하고, Attention Score를 구한다.
- 뿐만 아니라 $\sqrt {d_k}$로 나눠주는 연산이 있는데, 이는 query와 key의 차원이 커질수록 내적값이 커져 softmax 출력값이 매우 작아지는 현상을 방지하기 위함이다.
참고로 이해를 돕기 위해 query를 하나의 토큰으로 설정했을 뿐, 실제로는 query 역시 입력 시퀀스 전체에 해당하므로 위 그림과 같다. 이렇게 Attention Score를 구하고, Softmax에 전달해 Attention Distribution을 구한다.
Multi-head attention
트랜스포머에서는 Self-Attention을 한 번만 하지 않고 여러 차례 계산한다. 하나의 self-attention 계산을 수행하는 것을 head라고 하는데, 논문에서는 총 8개의 head를 사용했다고 한다.
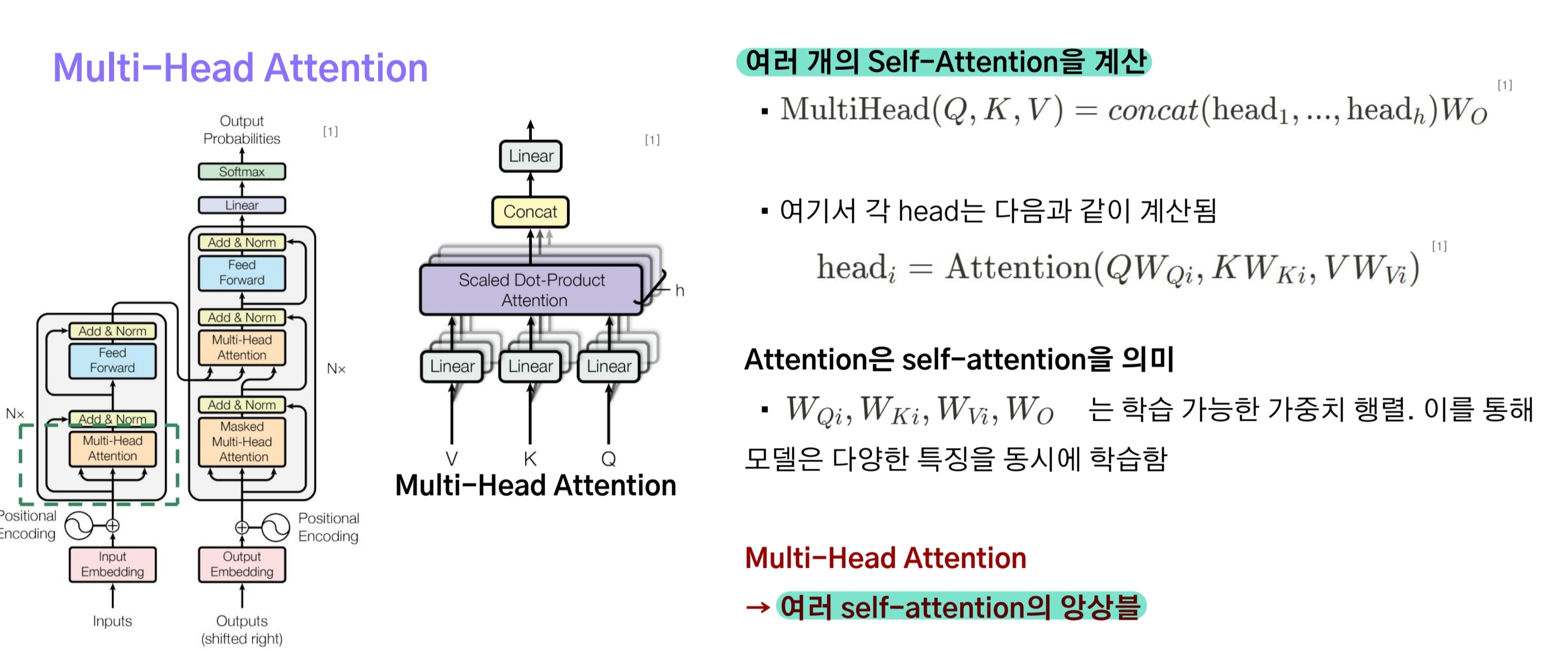
이렇게 여러 개의 head를 사용하는 이유는 Q, K, V를 구할 때 서로 다른 가중치를 갖는 Linear layer를 사용함으로써 self-attention을 앙상블 하는 효과를 만들기 위함이다.
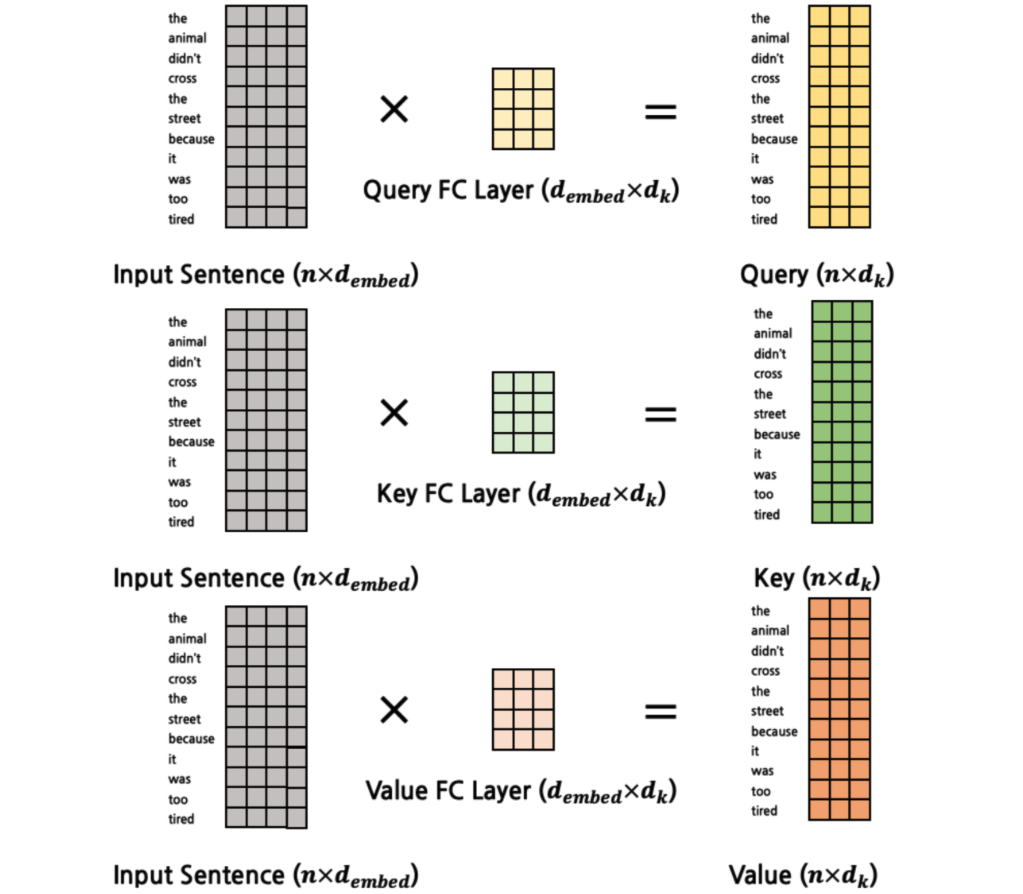
위 그림은 하나의 head가 입력받는 Q, K, V를 계산하는 것을 도식화한 것으로, 이와 같은 과정이 8개의 head에서 동일하게 수행된다.
다만, 실제 구현을 할 때는 Q, K, V를 계산할 때 d_model // num_heads = d_k를 출력 차원으로 설정하지 않고 d_model로 설정해 3개의 linear layer만 사용한다.
쉽게 말해 한 번에 8개의 Q, K, V를 구한 다음, Self-Attention을 계산할 때 분할을 수행하는 방식이다.
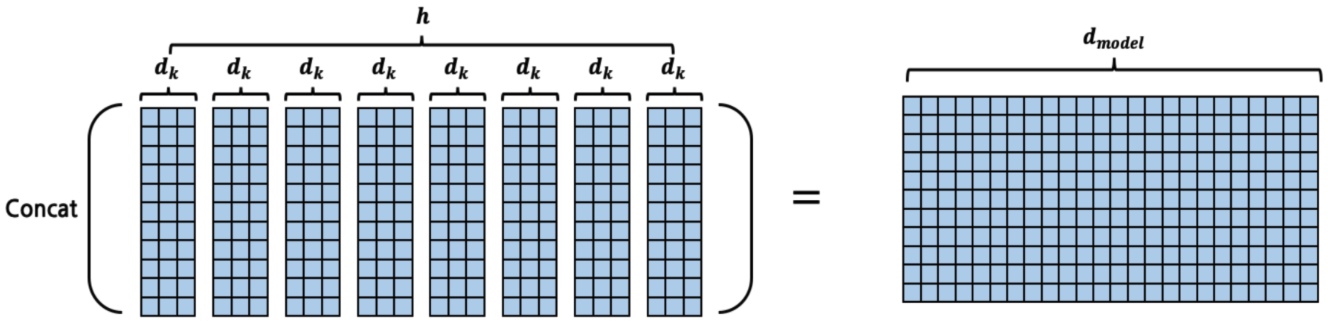
8개의 head에서 계산된 Attention Value [batch_size, seq_len, d_k]는 Concat되어 [batch_size, seq_len, d_k, num_heads]가 된다.
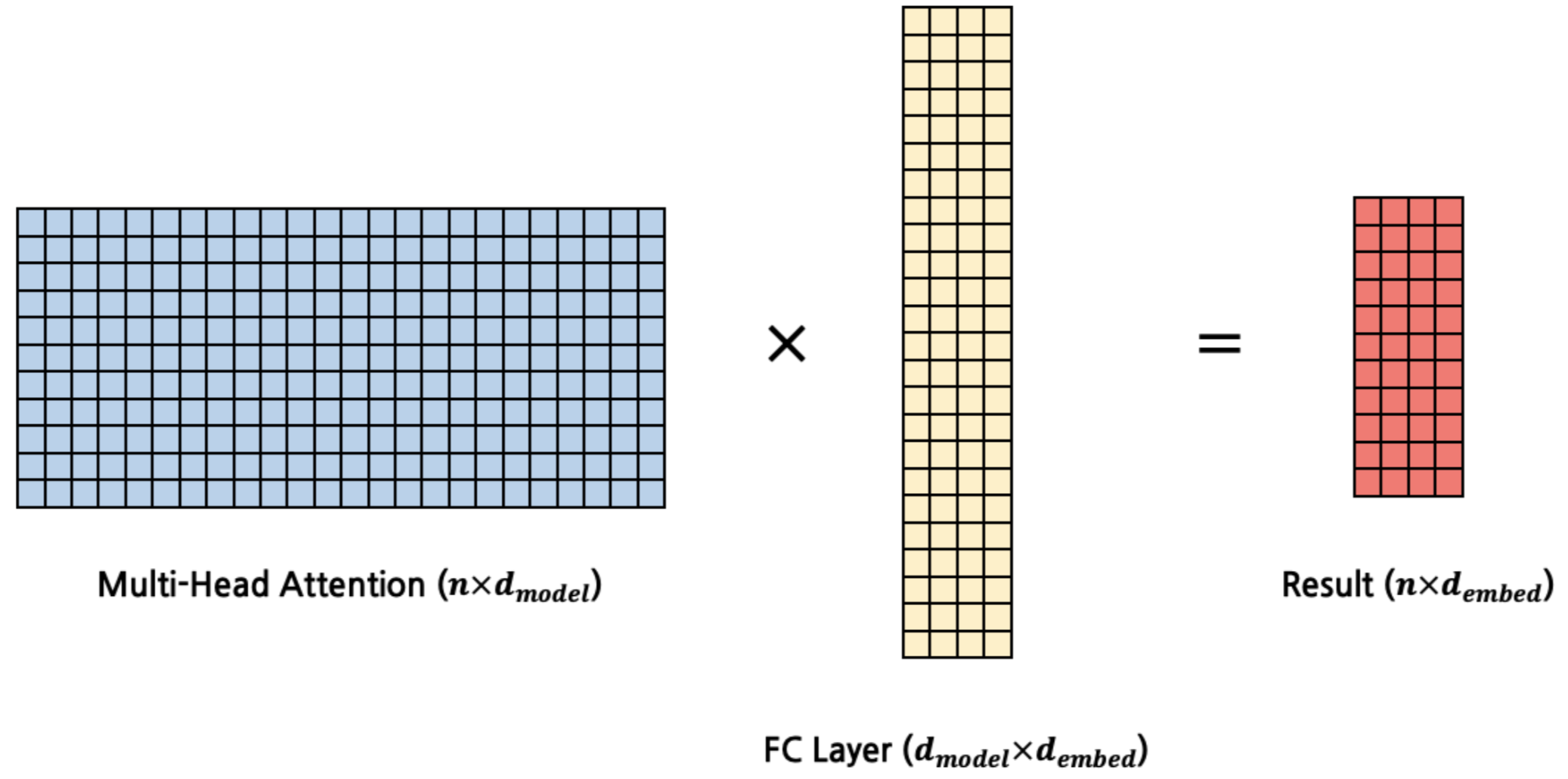
마지막으로 Multi-head attention matrix를 $d_{model}\times d_{model}$의 가중치 행렬을 갖는 linear layer에 입력시켜 $\text{seq len}\times d_{model}$ 행렬을 구하면, Multi-head Attention이 끝나게 된다.
3-3.Addition & Layer Normalization
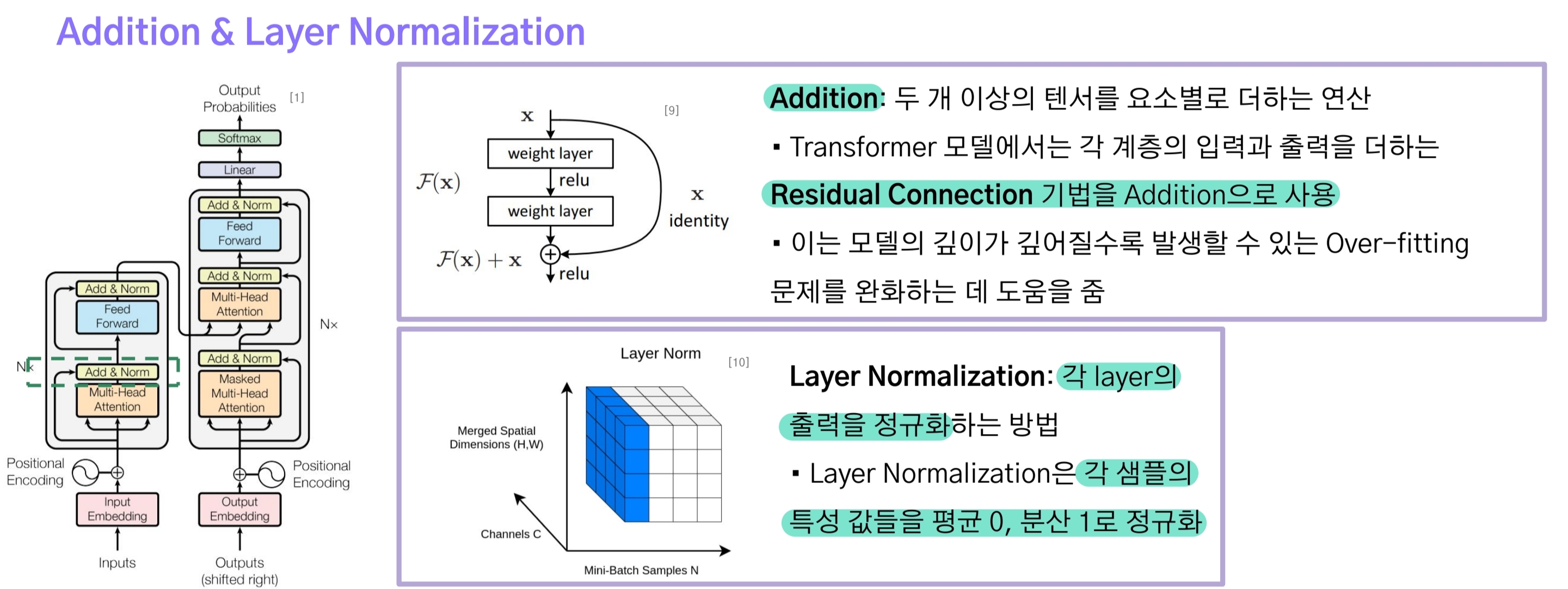
Multi-head Attention의 출력은 입력에 더해지는 skip-connection을 계산한다.
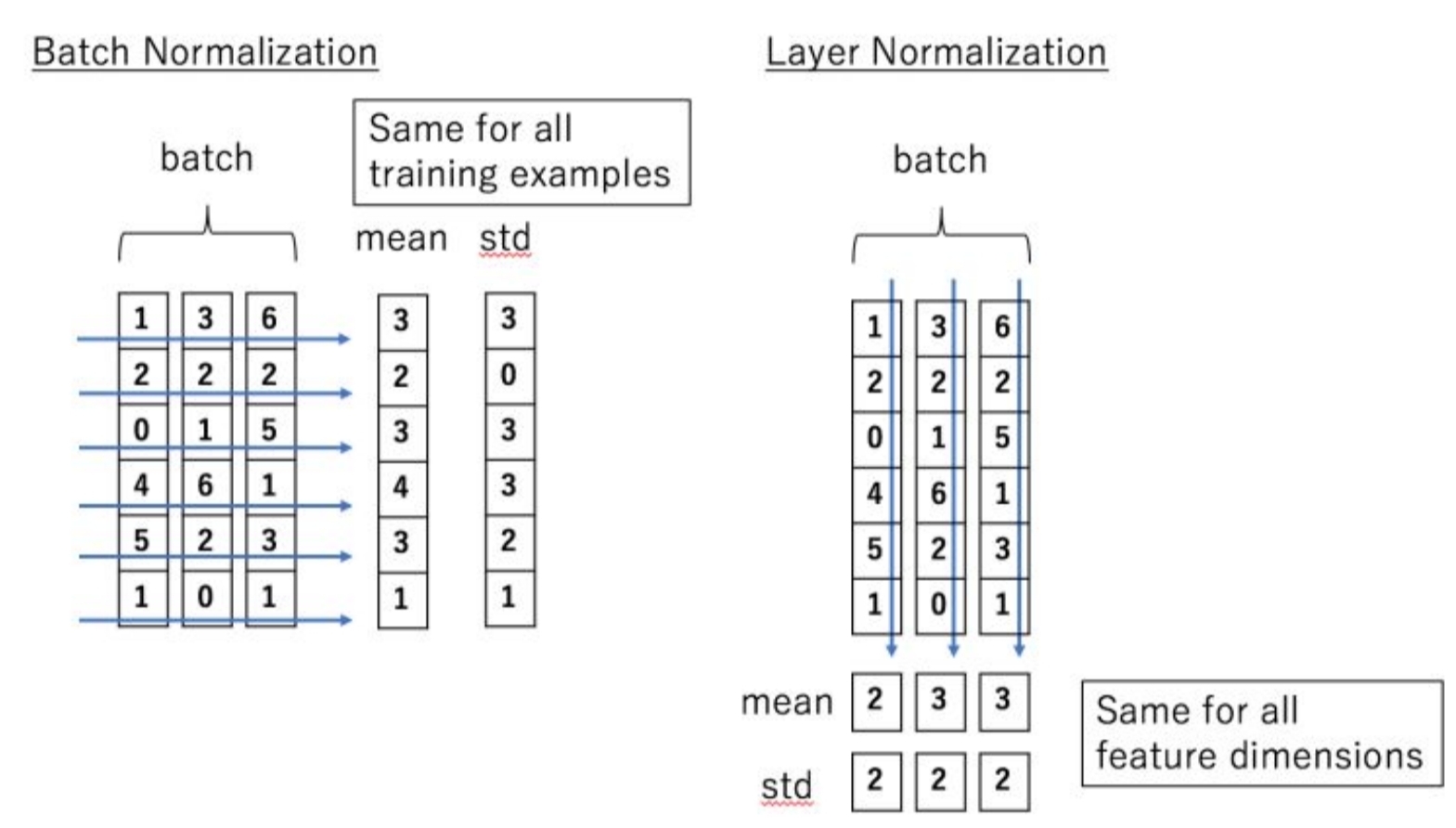
skip-connection 결과에 Layer Normalization을 적용하게 되는데, Batch-Normalization과의 차이점은 다음과 같다.
- batch norm은 배치 단위로 평균0, 분산1이 되도록 정규화한다.
- 이는 배치 크기(batch_size)가 작아지면 문제가 발생하며 시퀀스 데이터는 길이가 가변적이기 때문에 부적절하다.
- 반면에 layer norm은 각각의 데이터샘플을 평균 0, 분산 1로 정규화함으로써 모든 time step마다 동일한 통계치를 갖게 된다.
- 즉, 배치 크기와 시퀀스 길이에 영향을 받지 않게 되므로 더 효과적인 정규화 방식이라 할 수 있다.
3-4.Feed Forward Networks
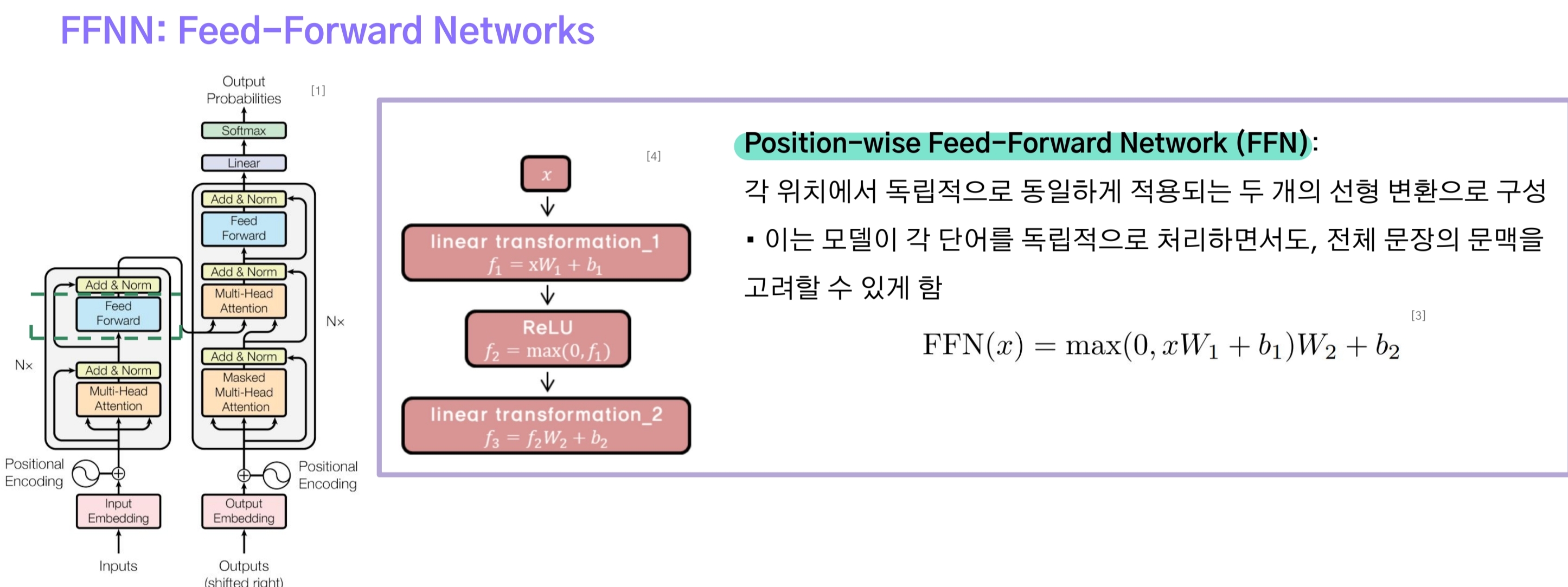
FFN은 multi-head attention의 출력을 입력으로 받아 (linear + ReLU)와 linear에 통과시키는 간단한 구조다.
이 층의 출력도 addition & layer normalization으로 전달된다.
3-5.Casual Attention(Masked Multi-Head Attention)
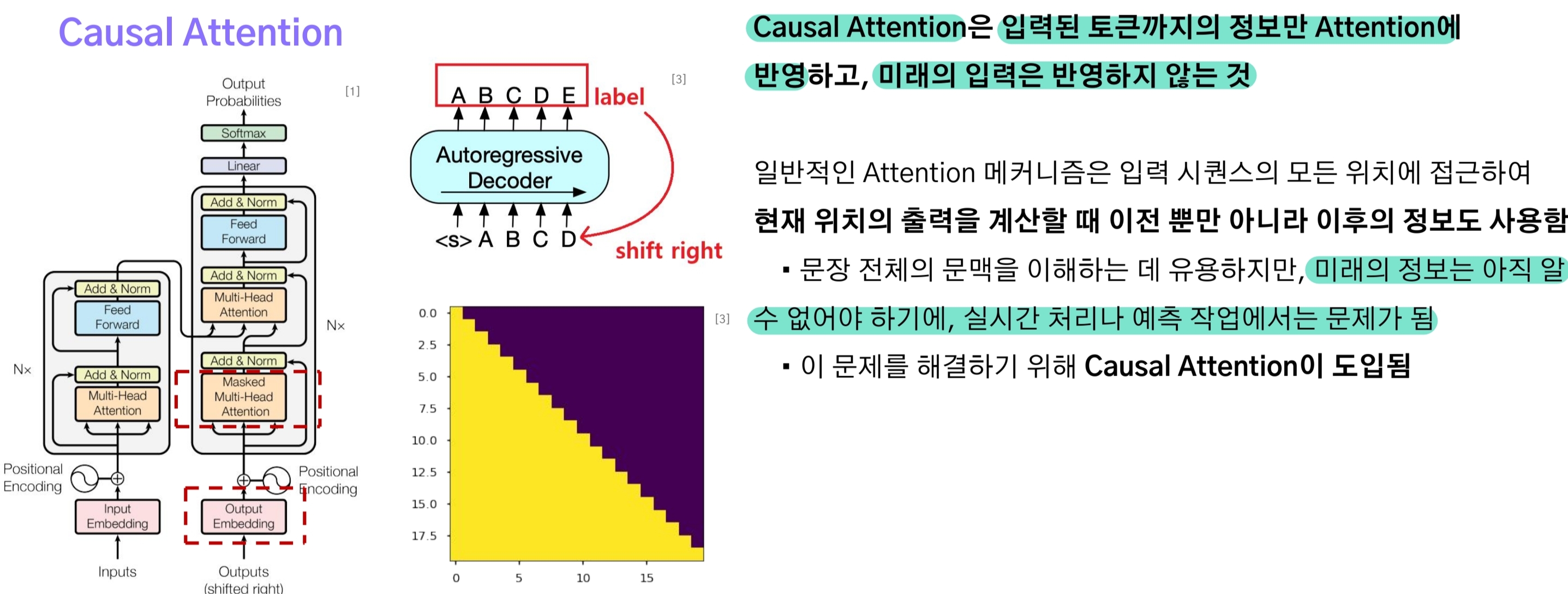
casual attention은 Decoder의 Self-Attention을 말한다. 이는 트랜스포머 특성상 시퀀스 데이터를 한 번에 입력 받기 때문에 다음 단계의 데이터들을 attention에 계산할 수 있게 되는 문제를 해결하기 위함이다.
쉽게 말해 맞춰야할 정답, 미래 정보를 볼 수 없게 만들기 위해 마스킹을 수행하는 것과 같다.
3-6.Encoder-Decoder Attention
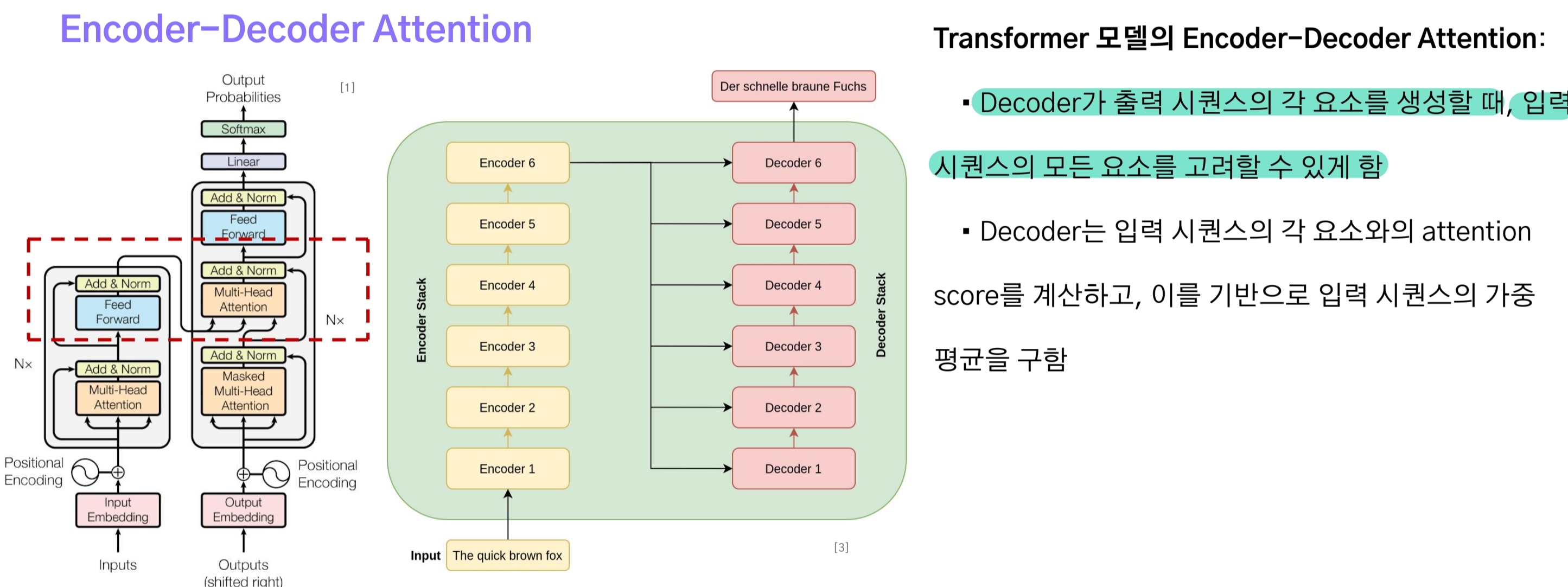
decoder의 casual attention 출력값은 encoder-decoder attention으로 전달된다. 이는 seq2seq의 attention처럼 decoder가 출력 시퀀스의 각 원소(토큰)을 생성할 때 입력 시퀀스의 모든 요소들을 고려할 수 있도록 하는 것이다.
3-7.Linear & Softmax
최종 Decoder stack의 출력 벡터를 target vocab 사이즈로 변환한다. 여기서 vocab size와 동일한 차원으로 변환하기 위해 linear layer를 사용하며, softmax를 거쳐 확률 벡터로 변환한다.
댓글남기기