[Upstage Ai-Lab]Seoul House Price Regression
[24.07.09 - 24.07.19] 서울시 부동산 가격 예측 경진대회
1.소개
이번 대회는 Upstage AI-Lab 3기에서 개최한 것으로 주어진 데이터를 활용하여 서울의 아파트 실거래가를 효과적으로 예측하는 모델을 개발하는 것이 목표다.
- 부동산은 의식주에서의 주로 중요한 요소 중 하나이며 부동산 자체의 가치도 중요하고, 주변 요소 (강, 공원, 백화점 등)에 의해서도 영향을 받아 시간에 따라 가격이 많이 변동된다.
- 개인에 입장에서는 더 싼 가격에 좋은 집을 찾고 싶고, 판매자의 입장에서는 적절한 가격에 집을 판매하기를 원한다.
- 부동산 실거래가의 예측은 이러한 시세를 예측하여 적정한 가격에 구매와 판매를 도와주게 된다.
- 정부의 입장에서는 비정상적으로 시세가 이상한 부분을 체크하여 이상 신호를 파악하거나, 업거래 다운거래 등 부정한 거래를 하는 사람들을 잡아낼 수도 있다.
1-1.데이터셋
기본으로 제공되는 데이터셋은 4가지다.
- 첫번째는 국토교통부에서 제공하는 아파트 실거래가 데이터로 아파트의 위치, 크기, 건축년도 등 해당 부동산이 갖는 정보들로 구성되어 있다.
- 두번째, 세번째 데이터는 서울시에서 자공하는 지하철역과 버스정류장에 대한 정보를 포함하고 있다.
- 네번째는 첫번째와 동일한 데이터지만 부동산 가격 정보가 포함되지 않은 테스트용 데이터다.
1-2.평가방식
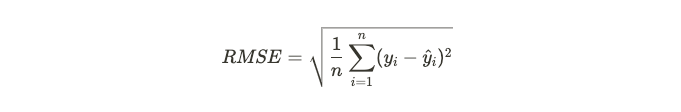
테스트 데이터에 대한 예측과 정답은 RMSE 함수로 입력되어 두 값 사이의 오차를 계산한다. 이 때 발생한 오차가 곧 모델의 성능이 얼마나 나쁜지를 나타내는 지표가 된다.
1-3.팀 작업방식
- 정규과정 시간인 평일 오전 10시부터 오후 7시까지 작업진행.
- 특별한 추가일정이나 사안이 있다면 오후 2시, 오후 5시에 회의를 진행하고 그렇지 않은 경우 6시에 개인별 작업 내용 공유.
- 각자 작업한 코드는 Github 저장소에 업로드하며 전처리한 데이터는 Google Drive를 사용해 공유한다.
2.데이터 기본 구조 분석
train.csv는 1118822개, test.csv는 9272개의 행으로 구성된 정형 데이터들이다.
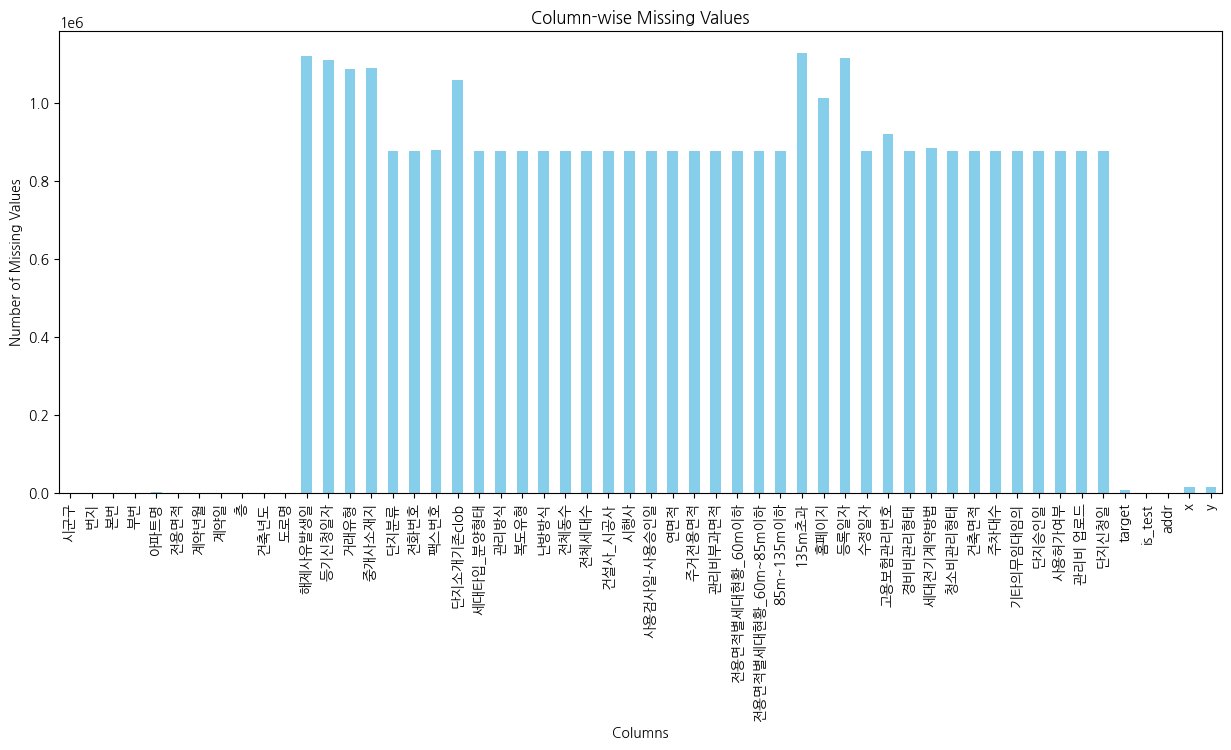
- train.csv는 53개의 컬럼, test.csv는 52개의 컬럼들로 구성되어 있다.(target 컬럼 미포함.)
- 그래프를 보면 알 수 있듯 결측치를 갖는 컬럼들이 굉장히 많다.
3.결측치 제거
3-1.크롤링
크롤링을 가장 먼저 선택한 이유는 정답을 인터넷에서 구할 수 있었기 때문이었다. 네이버 부동산, 다음 부동산, 직방과 같은 여러 가지 부동산 플랫폼들이 존재했으며 해당 건물에 대한 상세 정보들을 어느정도 제공한다. 하지만 이 방법은 다음과 같은 단점들을 갖고 있다.
- “아파트명” 컬럼 자체가 무의미한 값으로 기재된 경우가 존재했기 때문에 “시군구” + “번지” 또는 “시군구” + “도로명”을 기반으로 해당 건물의 정보를 찾아낼 수 있어야한다.
- 하지만 네이버 부동산의 경우 주소를 검색했을 때 해당 부동산의 이름을 제공할 때도 있지만 그와 관련된 모든 부동산 정보들을 제공하기 때문에 검색 알고리즘 로직이 꽤 많이 복잡해진다.
- 또한 현재 2024년 기준으로 해당 부동산이 재건축된 경우 정보를 찾을 수 없다는 점이다.
다행히 모든 데이터가 고유한 값이 아니였지만 고유한 주소를 추출했을 때 약 9천개정도의 주소들이 존재함을 확인했다. 결국 시간을 많이 소비하더라도 정확한 값으로 결측치를 채울 수 있다고 생각하여 크롤링만 일주일정도 개발했다.
하지만 애석하게도 크롤링으로 채운 값이 데이터셋과 정확하게 일치하지 않는 문제가 있었는지 아니면 원본 데이터셋의 분포를 왜곡시켜서인지 submission을 제출했을 때 처참한 결과를 얻게 되었다.
3-2.상관관계 분석 및 변수(컬럼) 삭제
두번째로 시도한 방식은 결측치가 많은 컬럼을 삭제하는 것이었고, 꽤나 효과적이었다.
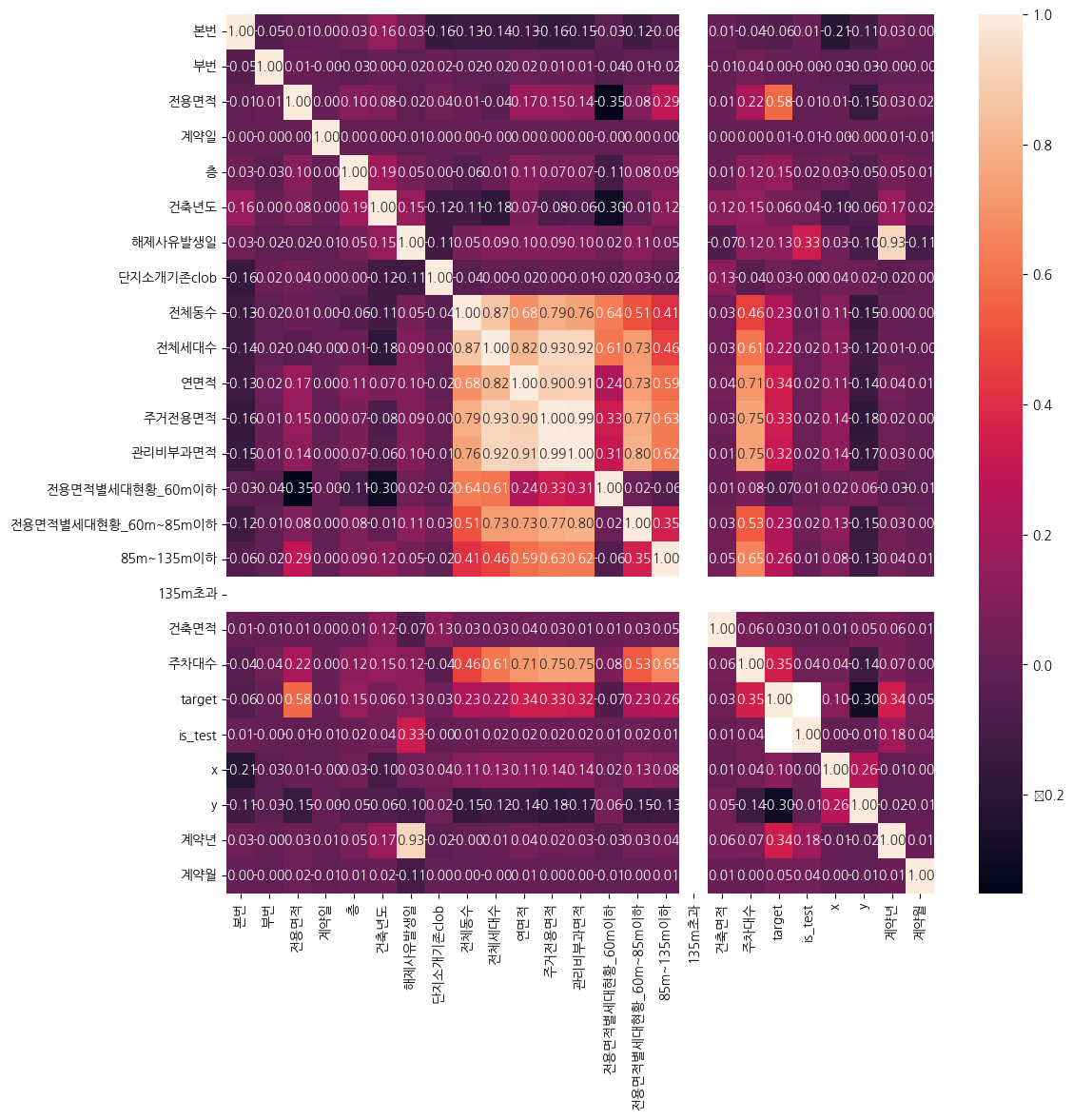
우선 target과 상관성이 있는 변수들이 어떤 것이 있는지 알아내기 위해 상관관계 분석을 진행했다. 사실 이 분석을 결측치나 이상치를 제거하지 않고 먼저 진행해도 되는건지 아직도 명확하지 않은데 이번 대회를 진행함에 있어서는 결과적으로 유효했다.
- 데이터셋이 가진 컬럼들 중 “해제사유발생일”, “등기신청일자”, “단지소개기존clob” 과 같이 부동산 가격에 영향을 주지 않을 것이라 생각되는 변수들이 결측치도 많이 포함하고 있었으며, 상관관계도 그다지 높지 않았다.
- 135m초과 컬럼은 다른 변수들과 아예 상관관계가 없고, 이와 유사한 “전용면적별 세대현황” 들도 그다지 높은 상관관계를 보이지 않는다.
전체 동수컬럼과전체 세대수,연면적,주거전용면적,관리비부과면적,전용면적별세대현황,주차대수들과 높은 상관관계를 보인다. 즉, 대단지 아파트일수록 세대수가 많고 주거면적과 관리비 부과 면적(커뮤니티 시설)이 많을 것이라 추측할 수 있다.- target은
전용면적,계약년월,연면적,주거전용면적,관리비부과면적과 높은 상관관계를 보이는데 이는 각각의 거래 데이터들이 “몇 평의 부동산을 언제 구매했는가”와 상관성이 높을 것이라 짐작할 수 있는 부분이다. - 나머지 변수들은 별다른 상관성을 보이지 않기 때문에 결측치를 처리하고 나서 다시 상관관계 분석을 하거나 효과적인 대체 방법이 발견되지 않는다면 과감히 삭제하는 것으로 방향을 잡았다.
4.변수 분석
4-1.전용면적과 target
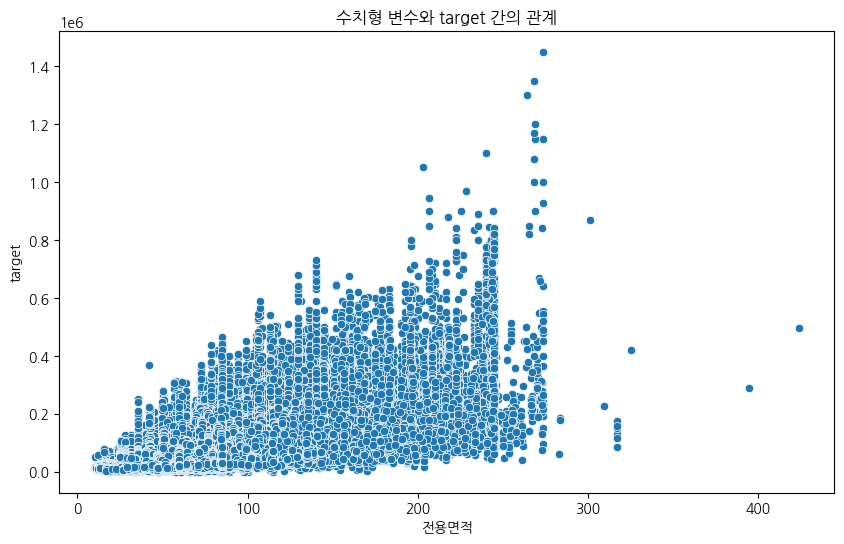
- 전용면적별 target값의 분포를 확인해보면 300m을 넘는 굉장히 넓은 면적임에도 최고가를 기록하지 못함을 확인할 수 있다. 즉, 무조건 넓다고 해서 비싼 것이 아니라 다른 요인들과 종합적으로 영향을 주게되는 것이라 해석할 수 있다.
- 다만 200~250m까지는 전용면적이 증가함에 따라 target도 우상향하는 경향을 보이고 있으므로 적절히 넓은 면적을 사람들이 선호하는 것이라 해석할 수 있다.
- 추가적으로 가족의 구성원이 몇명인가에 따라 구매하는 부동산의 면적도 어느정도 추론이 가능하겠지만 아쉽게도 이 부분은 시도하지 못했다.
4-2.계약년월과 target
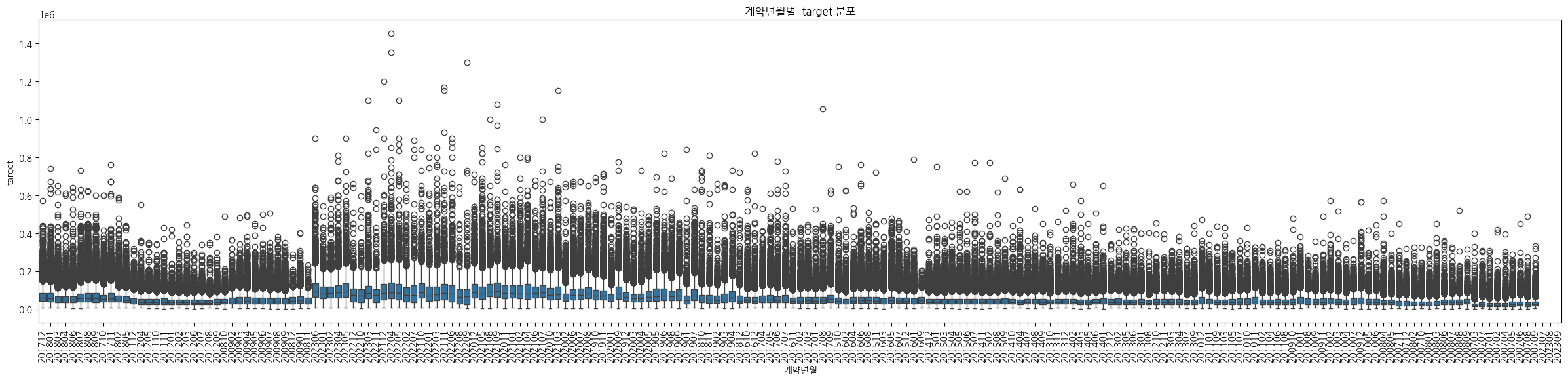
구매자가 계약한 년,월에 따른 target의 붙포를 보면 굉장히 변동폭이 큰 것을 알 수 있다.
- 단편적으로는 부동산별로 자체적인 가격이 다르다고 해석이 가능.
- 세부적으로는 부동산이 어디에 위치하고 있는지, 또 한국의 특성상 대출을 받아 임대나 매입을 하기 때문에 금리, GDP 같은 경기상황과도 연관이 있을 것이라 생각한다.
4-3.시군구와 target

다음으로 각각의 구마다 가격의 최대값과 평균값을 측정해봤다. 결과에서 확인할 수 있듯 강남구가 최대값이나 평균값이 최고가임을 확인할 수 있었다.
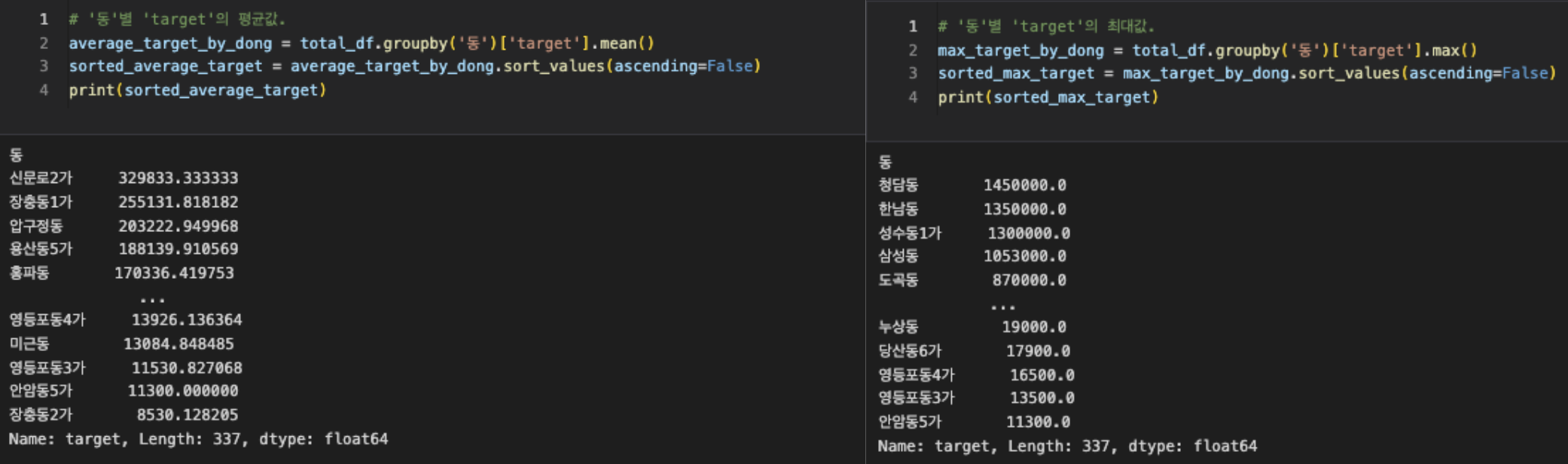
하지만 앞서 나온 결과는 동별로 확인해보면 성립하지 않는다. 최대값의 경우 강남에 속한 청담동만 top3안에 포함되어 있으며 평균값은 신문로, 장충동과 같이 강남이 아닌 다른 구에 속한 동이 더 높았다.
이러한 결과를 놓고 봤을 때 각각의 부동산은 어떤 구, 동에 소속되어 있는지에 대한 영향력이 절대적으로 높지는 않고 해당 부동산이 갖는 스펙이나 근처 교통, 편의, 문화시설 등의 추가 요인들과도 영향이 종합적인 것을 확인할 수 있다.
4-3.층, 건축년도
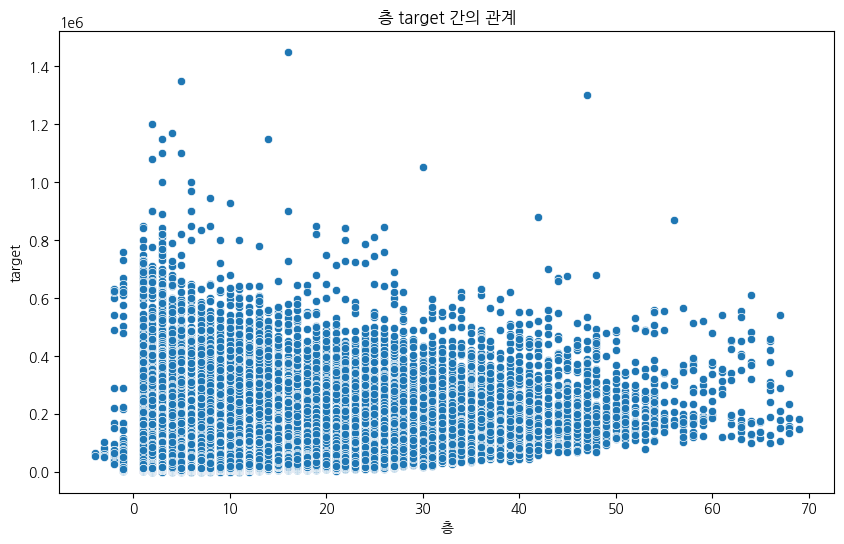
층별 가격의 분포를 보면 초고층에 가까워질수록 target의 수가 감소하는 것을 확인할 수 있다. 굉장히 고층 건물이라는 뜻은 그만큼 기술력이 있는 건설사가 시공한 것이기 때문에 가격의 저점자체는 평균적으로 높지만 데이터 포인트의 수가 적으며, 오히려 20층 이내에서 많은 포인트가 보인다.
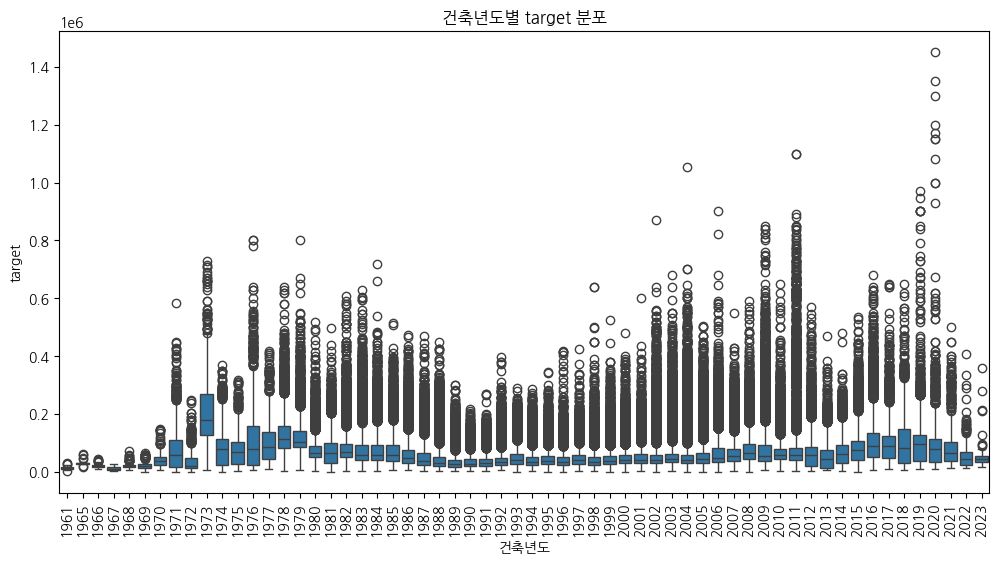
- 오래된 아파트임에도 target의 중간값에 위치한 부동산들이 존재.(한국에서 부동산은 투자종목이기 때문일까??)
- 1989년부터 1995년까지 대체로 target이 낮은 구간 존재.
- 1996년부터 2011년까지는 우상향하다가 2012년부터 급락. 이후 2020년부터는 급등.
4-4.건설사

모든 아파트가 그런 것은 아니지만 시공사에 따라 아파트에 브랜드가 부여되어 프리미엄가격이 책정되기도 한다. 즉, 동일한 스펙을 가진 부동산이라 하더라도 어떤 건설사가 시공했는지에 따라 적용되는 브랜드가격이 추가 가격으로 반영될 것이며 이는 곧 어느정도의 단가를 결정하는데 도움이 줄 것이라 판단했다.
랭크를 부여하는데 실험한 두 가지 방법은 다음과 같다.
- 데이터셋에 있는 건설사별로 시공한 건물가격들의 평균가를 기준으로 랭크를 부여.
- 빈도수 + 시공한 건물가격들의 평균가로 랭크를 부여.
이 중 첫번째 방법이 validation RMSE를 줄이는데 더 효과적이었지만 아쉽게도 리더보드 점수로는 제출 횟수 제한으로 인해 두 가지 방식을 각가 평가할 수는 없었다.
4-5.나머지 변수들
앞서 언급한 변수들을 제외한 나머지 변수들은 결측치가 많거나 의미 없는 값들로 구성된 것들이 많다. 이것을 어떻게 하면 대체할 수 있을까 고민을 많이 해봤지만, 상관관계도 크게 높지 않고 크롤링 데이터를 반영했을 때 악영향을 준 시점에서 결측치를 채울 수 있는 효과적인 방법이 없다고 판단해서 과감히 삭제하기로 했다.
5.추가 변수
5-1.지하철역과 버스정류장
두 가지 데이터에는 각각의 역마다 위도와 경도가 포함되어 있다. 또한 train, test에도 위도, 경도가 포함되어 있기 때문에 geopy 라이브러리를 이용해서 각 데이터별 최근접 역, 최근접 정류장과의 거리 그리고 인접한 역의 수, 인접한 정류장의 수를 측정하여 추가 특징으로 부여했다.
5-2.GDP와 기준금리
한국은행 사이트에서 연도별 기준금리와 GDP 데이터를 얻을 수 있었다. 이는 년도, 월별 대한민국의 경기상황을 나타내며 경기가 활황일수록 부동산 가격은 올라갈테니 굉장히 영향력이 클 것이라 판단해 각 데이터의 계약년도 컬럼과 연계했다.
6.모델학습
6-1.베이스라인
- 전처리된 데이터를 가지고 LightGBM 모델을 학습시켰다.
- 데이터의 수는 많지만 변수의 수가 많지 않으며 GPU 활용이 가능했기 때문에 학습 속도가 빠르고 일반적인 성능도 가장 높은 LightGBM을 선정했다.
RandomSearch,Grid Search를 이용해 최적의 하이퍼파라미터 조합을 찾으려고 했다.- Public Score : 19472.2764, Private Score : 14292.9526
6-2.타임시리즈
- 추가적인 변수를 도입하는 것도 좋겠지만, 학습의 전략으로도 충분히 성능이 개선될 수 있을 것이라 판단해 테스트 데이터의 구성을 분석.
- 그 결과 train 데이터셋은 2007년 1월부터 2023년 6월까지, test 데이터셋은 2023년 7월부터 2023년 9월까지로 구성된 것을 알 수 있었다.
- 즉, 3개월치의 미래 데이터들에 대한 예측을 수행할 수 있어야하므로 3개월 단위로 학습 데이터를 분할하고 검증 데이터는 학습 데이터의 미래 3개월치로 구성시켜서 학습.
- 안타깝지만 다른 팀원들이 가능한 제출 횟수를 모두 사용해버려서 이 학습 전략의 결과는 알 수 없었다.
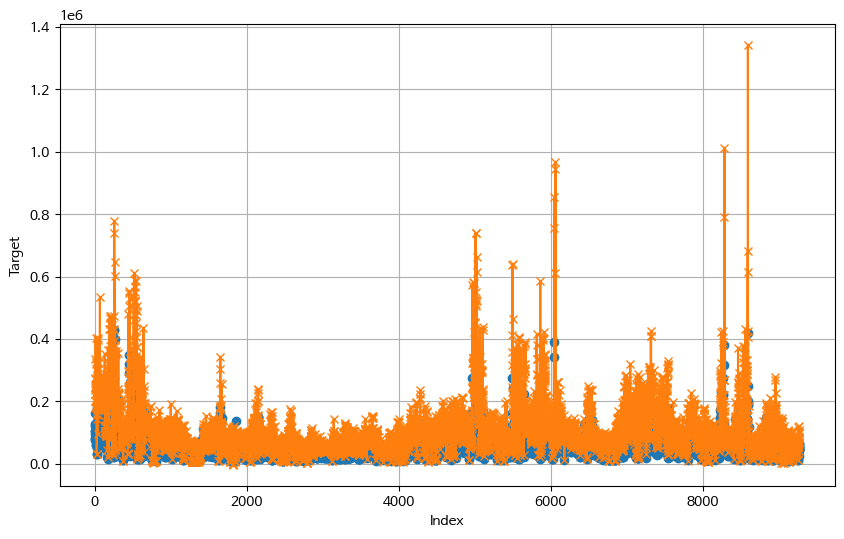
아쉬운 마음에 현재 팀에서 최고성적을 낸 submission과의 비교를 진행해 시각화를 해봤다. 주황색이 최고점수 모델의 예측값이고 파란색이 내가 만든 시계열 학습 모델이다. 시계열 학습 모델이 전반적으로 낮은 값을 보여주고 있으며 주황색 선보다 변동폭도 작은 형태임을 확인할 수 있다. 물론 이것은 모델간 결과 비교이기 때문에 리더보드 점수와 직접적으로 연관되지 못하기 때문에 참고정도만 하자.
7.회고
일단 아쉬움이 많이 남는 대회였다. 크롤링으로 결측치를 정확한 값으로 채울 수 있다는 기대감으로 검색 자동화 로직에 많은 시간을 할애했지만 어떤 이유인지 리더보드 점수는 굉장히 좋지 못했다. 멘토님의 피드백은 원본 데이터가 가진 분포를 왜곡시켰기 때문일 가능성이 가장 크다.였지만 여전히 정답에 가까운 값으로 결측치를 제거하려고 했음에도 왜곡이 발생한다면 예측이나 대체 같은 방식은 더 크게 왜곡되어야 정상 아닌가? 라는 의문이 남는다.
결과적으로 통계학적 지식이 너무 약하기 때문에 이러한 문제가 발생하지 않았나라고 생각하고, 이렇게 명확하게 해석이 어렵거나 시간이 많이 소모된 경우 과감하게 변수를 삭제시키는 것도 좋은 선택이라고 볼 수 있을 것 같다. 다음부터는 데이터에 대한 분석을 차근차근히 해본 후에 크롤링이 과연 필수적일까?라는 질문을 스스로에게 해보면 좋을 것 같다.
댓글남기기