[Upstage Ai-Lab]Dialogue Summarization
Upsatage x FastCampus AiLab 3기 - 문서 이미지 분류 경진대회
1.대회소개
본 대회는 upstage와 fastcampus가 주관하는 AiLab 3기에서 진행된 Dialogue Summarization의 개인 레포트입니다.

팀은 저를 포함해 총 4명으로 구성되어 있으며, public 7위, private 4위로 마무리하였습니다.
2.데이터 개요
- DialogueSum을 한국어로 번역한 데이터입니다.
- train, dev, test로 총 3개의 csv 파일이 제공됩니다.
- train : 12457, dev : 499, test : 499
- train과 dev는 [fname, dialogue, summary, topic]으로, test는 [fname, dialogue]로 구성됩니다.
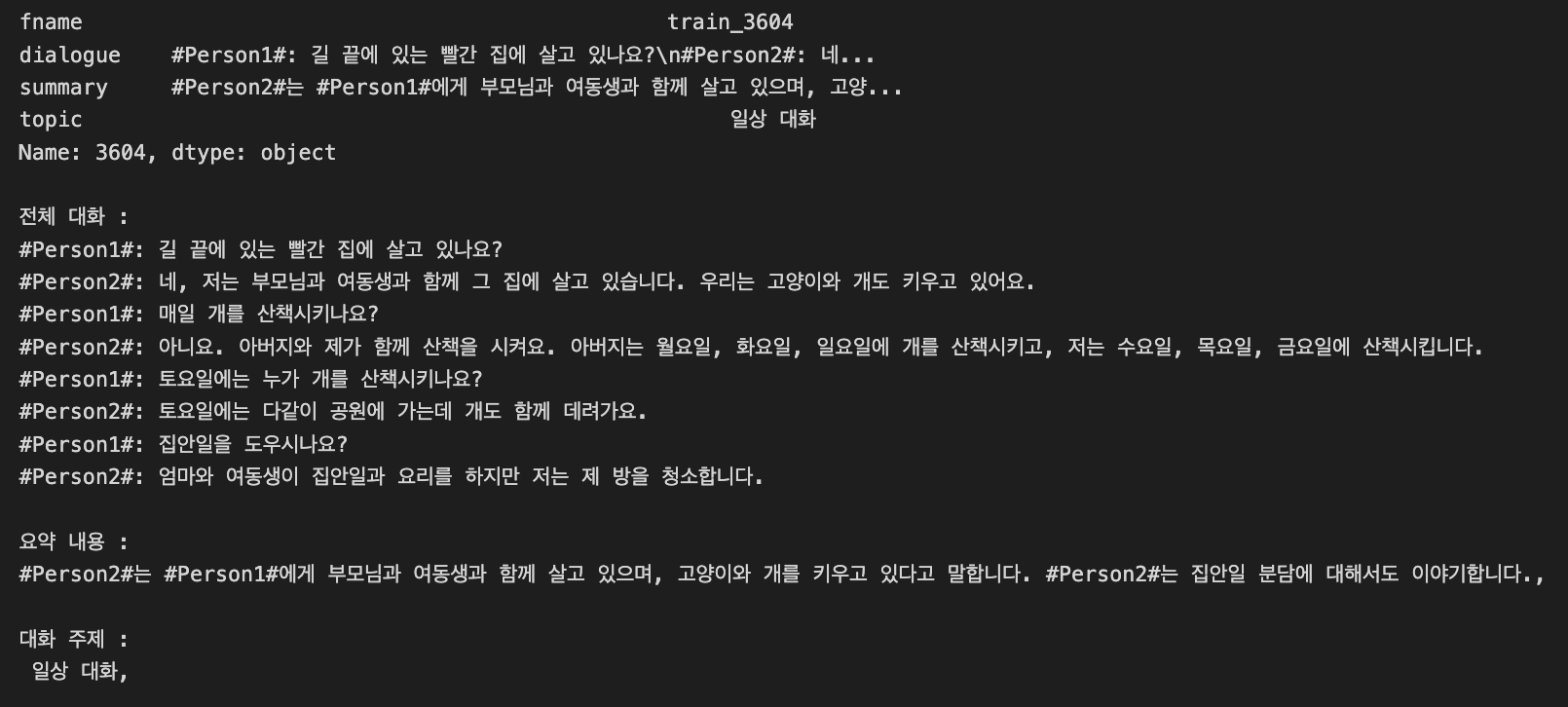
train, dev 데이터는 위와 같이 두 명이상의 사람들이 대화한 내용(구어체)이 있었고, 그에 대한 요약문(문어체)이 제공됩니다.
반면 test 데이터는 dialogue가 대화체이기 때문에 학습 성능과 리더보드 점수간 불일치가 발생했습니다.
3.베이스라인 구축
3-1.데이터 전처리
학습 데이터는 다음과 같은 전처리 과정이 적용되었습니다.
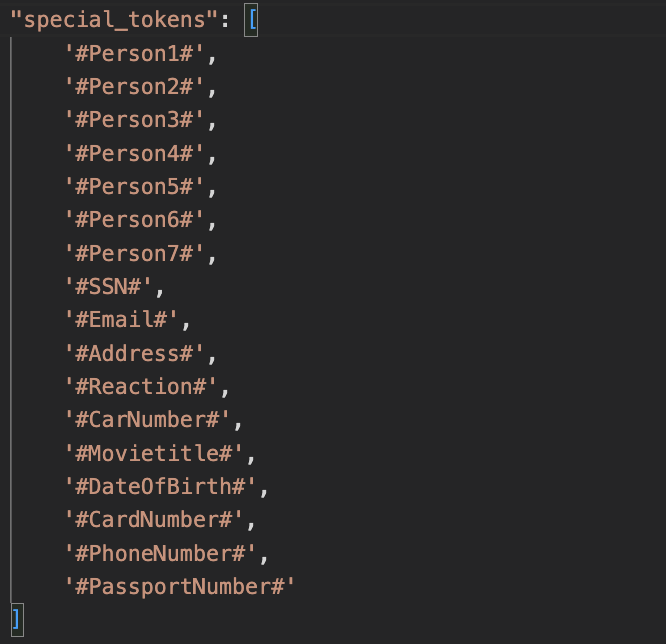
- 화자 #Personi#의 턴(turn)이 종료됨을 모델이 이해할 수 있게 하기 위해
<sep>토큰을 추가합니다. - ‘ㅋㅋ’와 같은 자음으로만 된 글자를 포함하는 경우 이를 제거합니다.
#문자열#과 같은 특수토큰들이 존재하는데 잘못 표기된 경우는 적절하게 변경합니다.- ‘아아아’, ‘스스스’와 같이 반복되는 글자들이 포함되는 경우 ‘아’, ‘스’와 같이 한글자만 남겨놓도록 처리합니다.
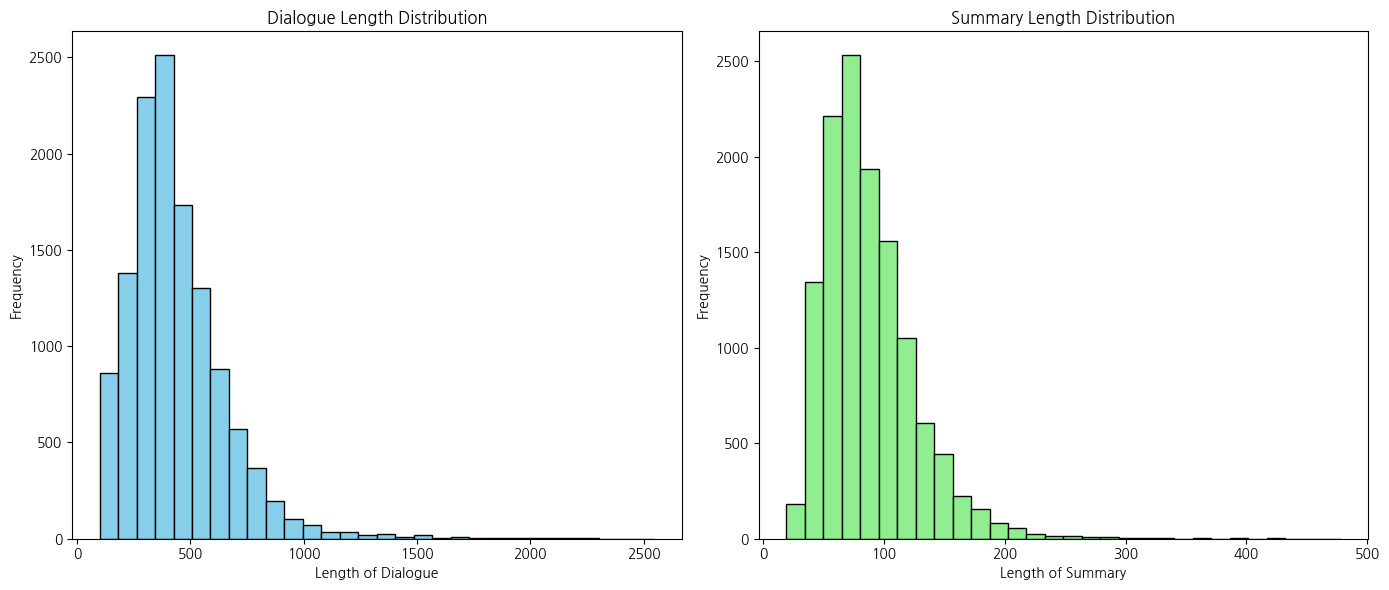
모델 학습시 encoder_max_len과 decoder_max_len, 추론시 generate_max_len을 설정해야합니다. 따라서 train, dev, test의 dialogue, summary에 대한 길이를 구해 시각화하고 가장 비중이 가장 많은 값으로 설정합니다.
3-2.모델 학습
학습 모델은 대회 Baseline 코드에 있는 Bart를 사용했고, 추가적으로 T5도 사용해봤습니다.
베이스라인 코드는 final result로 41.66, 전처리를 추가했을 때 41.67이라는 점수를 받았습니다.
4.문제점
- huggingface에 있는 pretrained weight를 사용했었는데, 한국어로 사전학습된 것들이 많지 않아서 선택지가 영어보다 작습니다.
- 자연어처리 작업에 대한 이해도가 부족해서 Tokenizer를 대회 데이터로 생성해놓고 pretrained weight를 사용하는 실수를 했는데, 이 작업에서 시간 소비를 굉장히 많이했습니다.
- 토크나이저를 새로 만들게 되면 Pretrained weight를 사용하지 못하고 새롭게 pretraining을 해야합니다.
- BartForConditionalGeneration은 CrossEntropy 손실을 사용합니다. 하지만 이는 단어 단위 손실을 계산하기 때문에 문장 전체에 대한 피드백이 부족해서 성능개선이 어렵다고 해석했습니다.
5.시도한 방법들
5-1.LLama3 + QLoRA
https://llama.meta.com/docs/how-to-guides/fine-tuning/
Bart, T5 모델들은 이런저런 시도들을 하더라도 점수가 향상되지 못했기 때문에 LLM 모델을 사용해보기로 했습니다.
모델은 LLama3-8B-int4를 사용했는데, 전체를 fine tuning하기엔 컴퓨팅 자원이 턱없이 모자랐기 때문에 QLoRA로 finetuning을 했고, 43점을 달성할 수 있었습니다.
5-2.Data Augmentation
train과 test간 어체 불일치가 있는 것을 파악할 수 있었습니다.
- SamSum 데이터셋을 한국어로 번역해 추가하고 대회 데이터를 Back translation해서 동의어 데이터 생성하고 학습시 44.6으로 1%개선.
- train(구어체)과 test(문어체)간 어체차이를 통일 시키기 위해 dialogue-to-summary, summary-to-dialogue 데이터 생성하고 학습시 45.72로 2%개선.
6.후기
일단 경험이 굉장히 중요하다는 점을 다시 한 번 느낄 수 있었습니다.
자연어처리에 대한 경험 및 이해도가 좀 있었다면 ‘토크나이징 + 사전학습’에 시간을 많이 허비하지 않았을 것이고, 그만큼 LLM 실험을 더 할 수 있었을 것 같습니다.
그래도 그만큼 경험치를 많이 쌓을 수 있었다고 생각하며, 성적도 7위에서 4위로 올라갔기 때문에 나름 유의미한 삽질이었다고 생각합니다.
- huggingface에서 pretrained weight를 사용해야하는데 이것 때문에 모델의 구조적인 변화를 주기에 굉장히 까다로웠다.
- 토크나이저를 새로 만들 때는 대규모 데이터셋을 이용한 Pretrain이 반드시 필요하다….
- 연구할 때는 이 과정이 거의 필수이지 않을까??
- 기업에서 서비스를 만들 때는 너무 많은 비용이 들어갈 것 같으므로 pretrained weight를 많이 사용할 것 같다.
- LLM 모델을 활용하는 방법에 대한 공부가 필요하겠다.(솔직히 튜토리얼 없었으면 LoRA라는게 있는지도 몰랐다.)
댓글남기기