AiLab 3기 - Information Retrieval 대회
GitHub
https://github.com/pervin0527/Upstage_Ai_Lab/tree/main/16-IR_Project
1.데이터 분석
1-1.Query 데이터셋
{"eval_id": 213, "msg": [{"role": "user", "content": "각 나라에서의 공교육 지출 현황에 대해 알려줘."}]}
{"eval_id": 107, "msg": [{"role": "user", "content": "기억 상실증 걸리면 너무 무섭겠다."},
{"role": "assistant", "content": "네 맞습니다."},
{"role": "user", "content": "어떤 원인 때문에 발생하는지 궁금해."}]}
{"eval_id": 276, "msg": [{"role": "user", "content": "요새 너무 힘들다."}]}
- eval.jsonl
- 220개의 쿼리들로 구성된 데이터셋.
- 주요 쿼리는 과학적인 상식에 대한 질문이다.
- 20개의 멀티턴 대화와 20개의 일상적인 대화들이 포함되어 있다.
- 따라서 멀티턴 대화를 한 문장의 쿼리로 정리하는 과정과 과학 상식 질문인지 분류하는 과정이 필요하다.
1-2.Document 데이터셋
{"docid": "42508ee0-c543-4338-878e-d98c6babee66", "src": "ko_mmlu__nutrition__test",
"content": "건강한 사람이 에너지 균형을 평형 상태로 유지하는 것은 중요..."}
{"docid": "4a437e7f-16c1-4c62-96b9-f173d44f4339", "src": "ko_mmlu__conceptual_physics__test",
"content": "수소, 산소, 질소 가스의 혼합물에서 평균 속도가 가장 빠른 분자는 수소.."}
{"docid": "284919ef-edaf-492d-9575-0a1b40416a71", "src": "ko_ai2_arc__ARC_Challenge__train",
"content": "겨울에 습한 공기가 차가운 표면과 접촉하면 결과적으로 서리가 생길 수 있습니다..."}
{"docid": "e0630bcf-365d-44da-989e-0c393796aaa9", "src": "ko_ai2_arc__ARC_Challenge__test",
"content": "환경에 가장 적은 피해를 주는 발전소를 건설하기 위해 한 공학자는 태양 전기 발전소를..."}
- documents.jsonl
- 4272개의 문서들로 구성된 데이터셋.
- MMLU와 ARC 데이터셋을 한국어로 번역한 데이터.
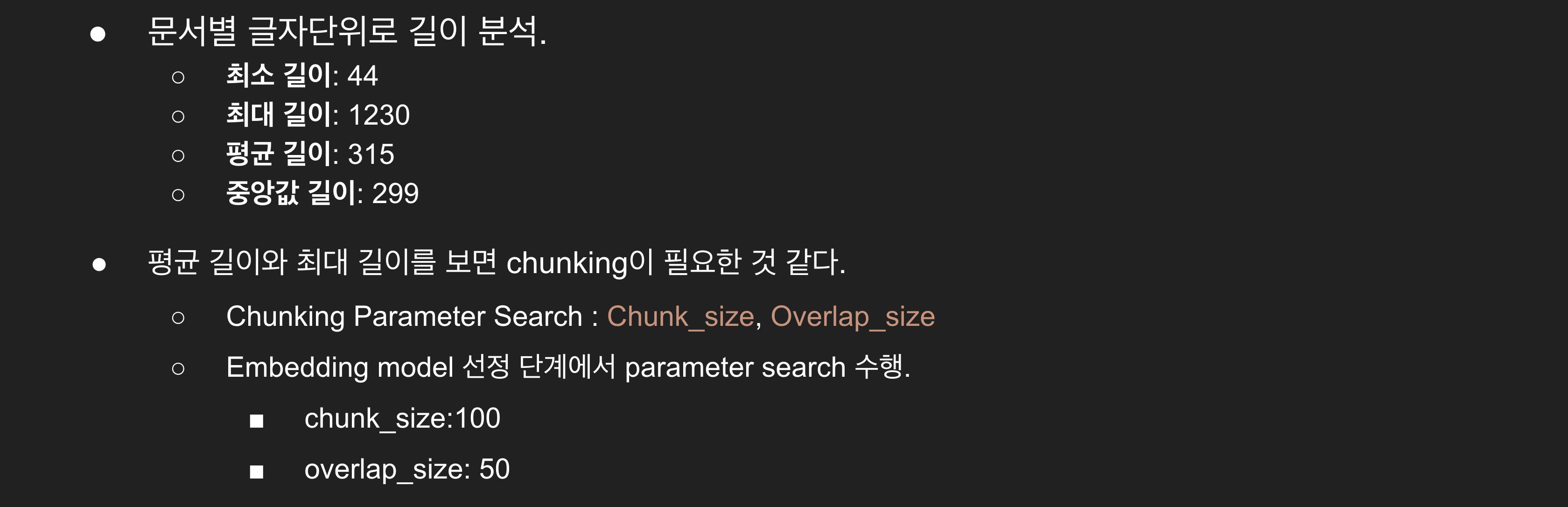
- 문서 길이가 평균 300자, 최대 1000자 이상이기 때문에 chunking을 해주는 것이 필요해보인다.
- 어떤 방법으로 chunking하는 것이 가장 효과적인지, chunk_size와 overlap_size는 어떤 값이 적절한지 실험이 필요하다.
2.Baseline
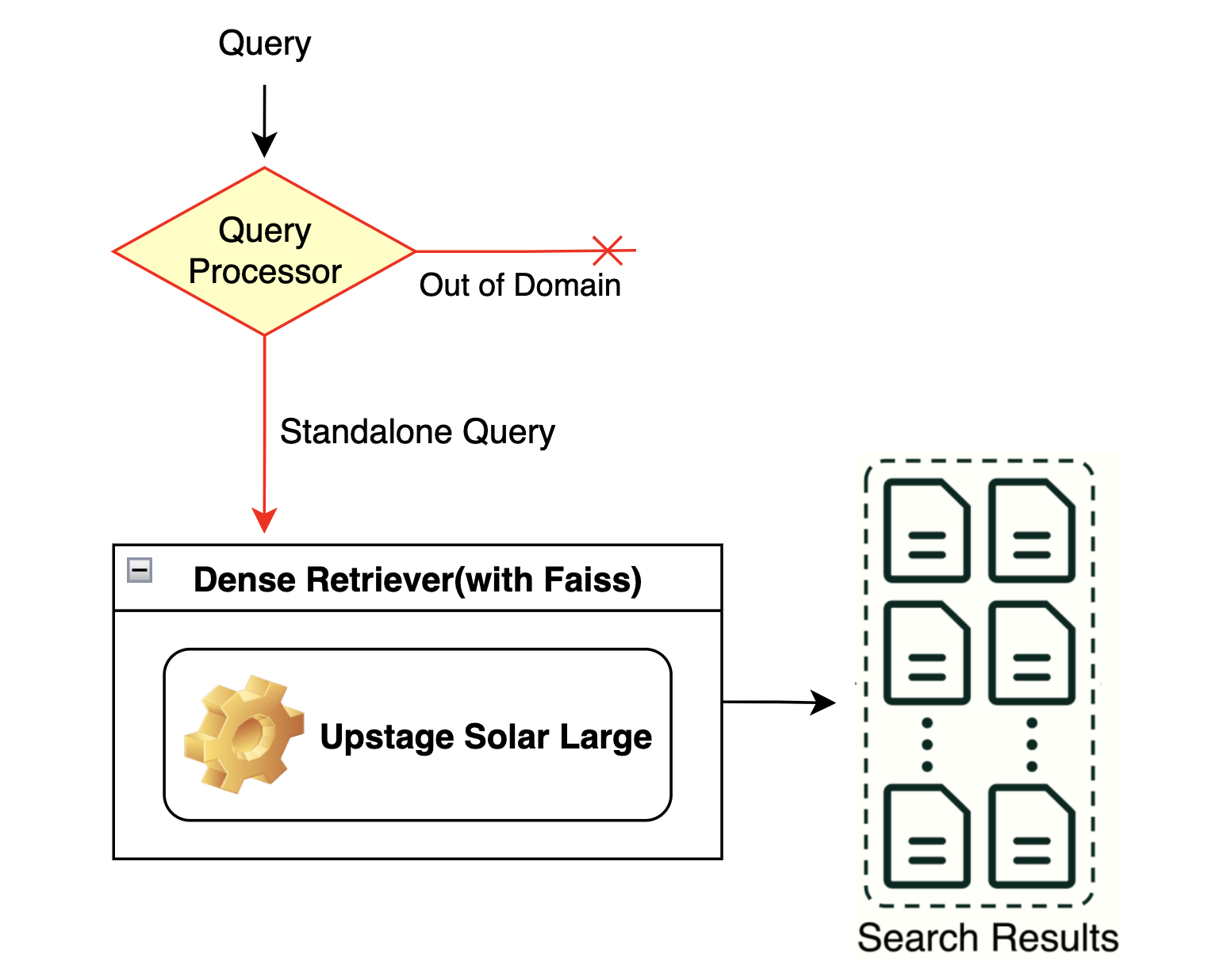
2-1.임베딩 모델 성능 선택을 위한 실험
Sparse(BM25)와 Dense(벡터 임베딩) 중 어떤 방식이 더 성능이 좋을지 비교하기 전에 적절한 임베딩 모델을 선별하는 과정이 우선이다.
- 대회 데이터셋에는 label이 없기 때문에 얼마나 검색 정확도가 높은지 정량적으로 평가할 수 없다.
-
따라서 대략적인 성능이라도 파악하기 위해 다음과 같은 과정을 수행.
- 문서마다 10개의 질문을 LLM(gpt-4o)이 생성한다.(생성된 질문은 문서와 동일한 docid를 포함.)
- 문서의 내용과 적절한 관련성을 갖는 질의임을 최소한으로 보장 받기 위해 GEval 3점 이상인 질의를 최대 3개 사용한다.
- 대회 평가 지표와 동일한 방식(MAP)으로 검색 결과를 평가한다.
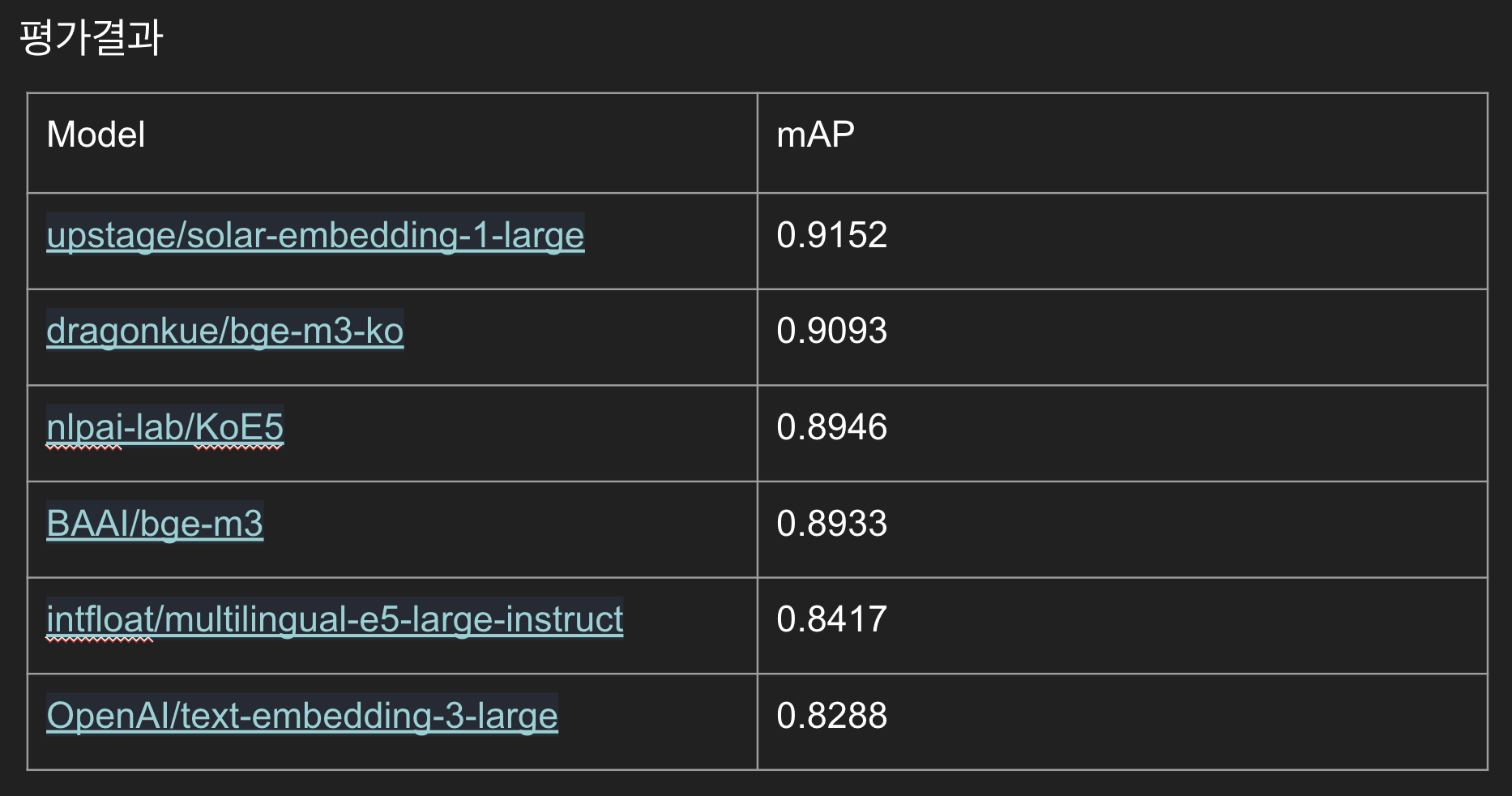
실험 결과 Upstage의 Solar-embedding-1-large가 0.9197로 가장 좋은 성능을 보여줬다.
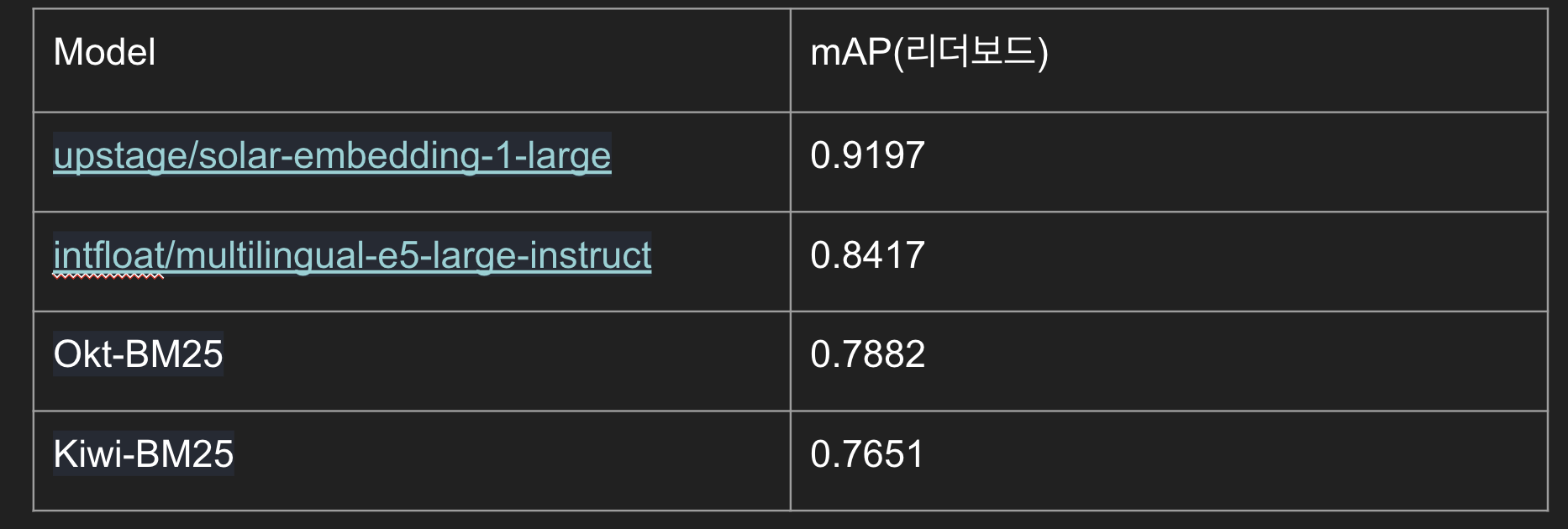
2-2.Sparse vs Dense
다음으로 Sparse 방식과 Dense 방식 중 어떤 방식이 더 좋은 성적을 내는지 평가한다. 이 실험은 대회에 적합한 방식을 찾기 위한 것이므로 리더보드 점수를 평가 기준으로 채택했다.
2-3.Query Expansion
쿼리 데이터셋을 분석했을 때 다음과 같이 애매한 것들이 존재한다.

이와 같은 쿼리들 뿐만 아니라 전체적인 쿼리 품질을 향상시키기 위해 LLM(gpt-4o)을 이용한 query expansion을 실험해봤다.
첫번째 실험으로 질문 의도를 파악한 후, 이를 더욱 명확히 하도록 개선했으나 점수는 감소했다.
- 원본 :
“나무의 분류에 대해 조사해 보기 위한 방법은?” - 확장 :
“식물학 및 생물학에서 나무의 분류 체계와 분류 방법을 조사하는 방법은 무엇인가요?” - mAP 0.9000
두번째 실험으로는 핵심 단어들만 추출해서 간단명료하게 개선했지만 이 방식 역시 점수가 감소했다.
- 원본 :
“나무의 분류에 대해 조사해 보기 위한 방법은?” - 확장 :
“나무를 분류하는 방법과 조사 방법은?” - mAP 0.9030
세번째는 LLM이 아니라 사람이 직접 질문 개선을 시도했다.

이 방법은 원본 쿼리가 가진 의도를 최대한 유지하려다보니 변화를 주기 까다로웠고 수정 자체가 어려웠던 질문들도 다수 존재했다.
2-4.Document Expansion
쿼리에 대한 변화가 효과적이지 못했으니 문서에 대한 변화를 시도했다.

문서별로 제목, 요약, 가설적 질문 등을 LLM으로 생성하고 추가하는 형태로 실험을 했는데 query expansion과 마찬가지로 성능이 개선되지 못했다.
3.Problems
3-1.실험 실패
앞서 수행한 실험들은 객관적으로 어떤 것이 문제인지를 판단하기 어렵다.
쿼리나 문서에 정보가 과도하게 추가되어 노이즈로 적용했다거나 원본보다 정보가 많이 손실되었다 등 모든 것이 주관적인 가설 해석이라 적절한 변화가 어느 정도인지 파악하기 어렵다.
3-2.정성 평가
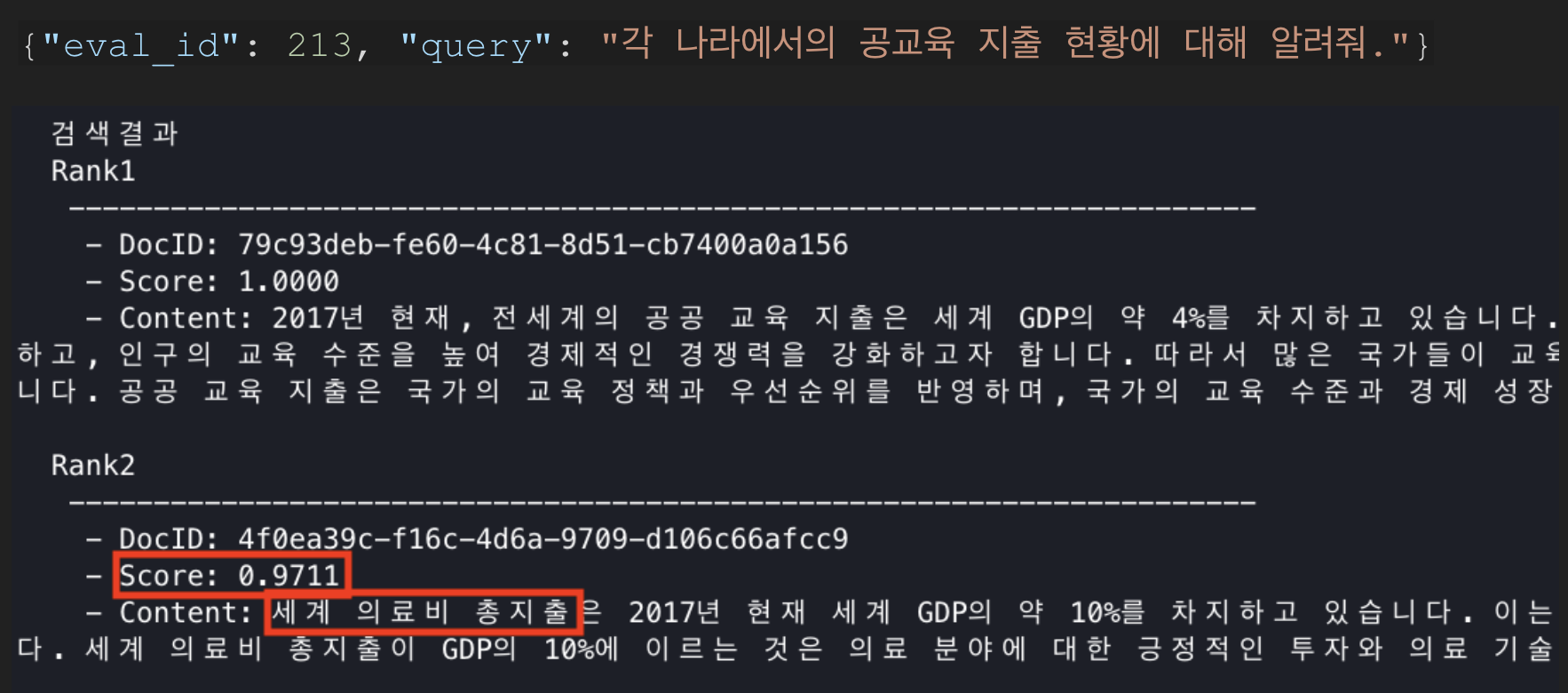
검색한 결과를 정성적으로 평가했을 때, 쿼리와 의미적으로는 유사하지만 핵심적인 키워드인 "공교육 지출"과 관련 없는 의료비 지출이 높은 유사도로 검색되고 있는 것을 확인할 수 있다.
4.개선시도
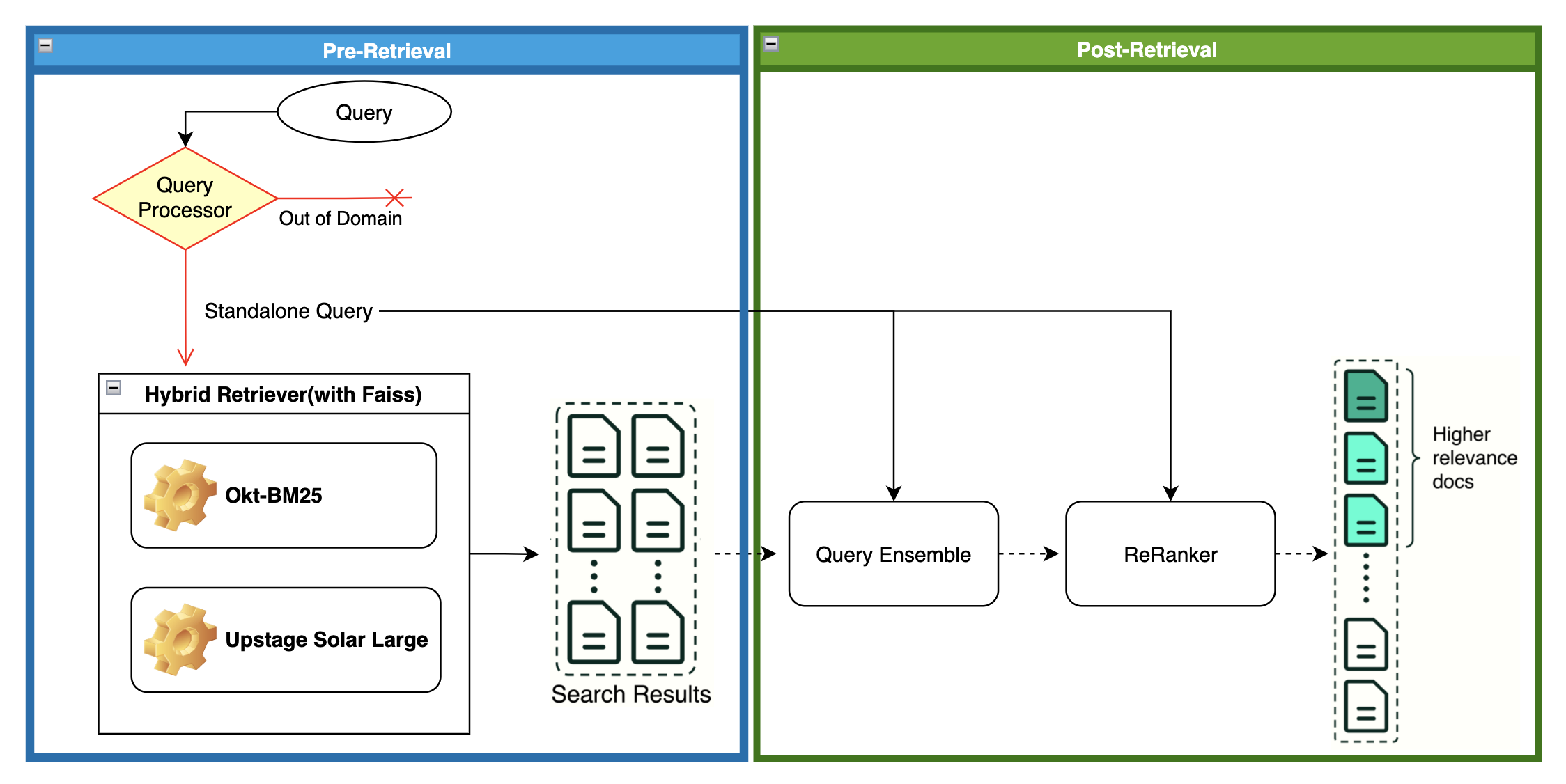
4-1.Ensemble Retriever(Hybrid Retriever)
- “복숭아 키우는 노하우 좀” 과 같이 특정 대상이 명확한 경우 BM25가 효과적일 것이므로, BM25를 벡터 임베딩과 하이브리드로 검색하는 Ensemble Retriever를 적용.
- Langchain은 RRF(Reciprocal Rank Fusion) 방식인데, 검색된 문서들의 유사도로 정렬 후, 낮은 순위일수록 큰 가중치를 부여하고 총합한다.
- CC(Convex Combination) 방식은 구현되어 있지 않으므로 별도로 구현했다.
a * BM25_score + (1 - a) * cos_sim - Sparse, Dense에 적용될 가중치는 parameter search로 탐색, [0.4, 0.6]로 설정.

- 두 가지 방식 모두 mAP가 약 0.1~0.2 증가하였다.
- 전반적으로는 CC 방식이 더 좋은 결과를 보였다.
4-2.Contextual Retriever
- 문서를 청크로 나누었을 때 쿼리와 관련성이 높은 청크는 소수. ➡️ 대부분의 청크는 질의와 관련성이 적다.
- Contextual Retrieval은 원본 문서와 청크를 LLM에 입력해서 청크에 문서의 문맥 정보를 간략히 채워주는 방법이다.
-
chunking으로 만들어진 24799개의 chunk별로 contextual retrieval을 적용한다.
- Before : “회사의 수익은 지난 분기 대비 3% 증가했습니다.” 해당 청크에서는 ‘회사'는 어떤 회사인지, ‘지난 분기'가 정확히 언제인지 알 수 없다. - After : “회사의 수익은 지난 분기 대비 3% 증가했습니다. 이 청크는 2023년 2분기 ACME corp의 실적에 대한 SEC 제출 자료에서 가져온 것입니다. 전 분기 매출은 3억 1,400만 달러였습니다. 회사의 매출은 전 분기 대비 3% 증가했습니다.” -
프롬프트를 고도화할수록 성능이 좋아진다.
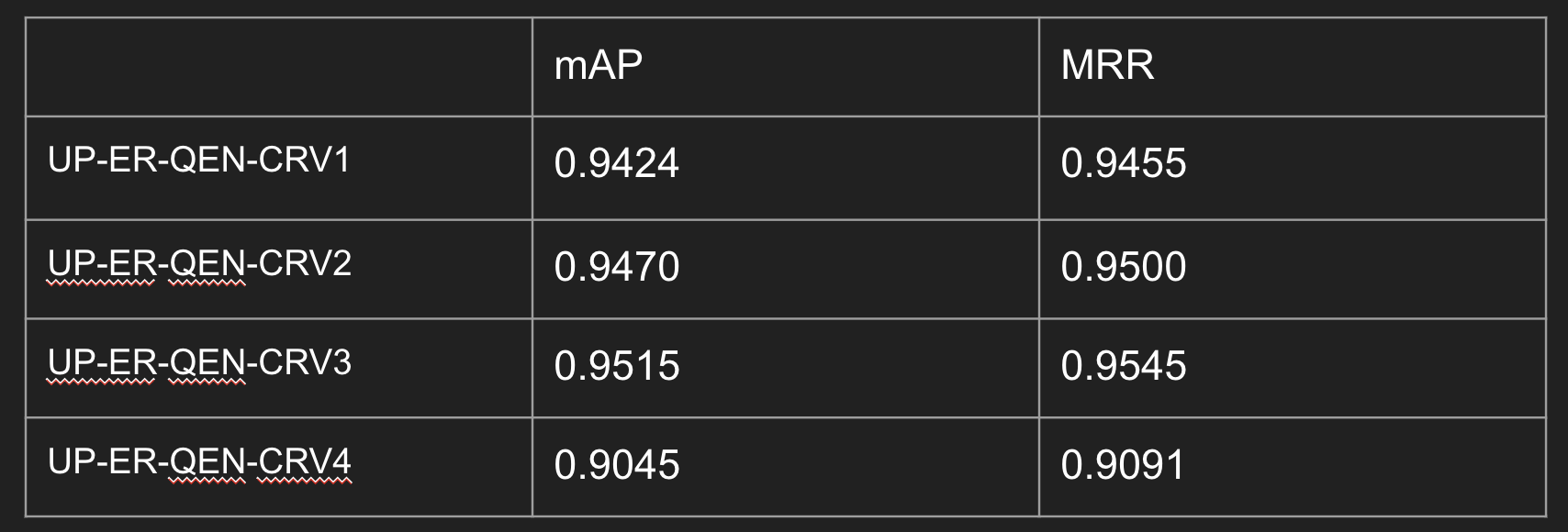
- version1 : normal
- version2 : 청크에 부족한 점을 먼저 찾은 후, 정보 추가하기
- version3 : few-shot 적용(ex.현재 청크에는 “회사명”, “정확한 날짜” 정보가 없습니다.)
- version4 : 제목, 요약 추가 ➡️ 과도한 정보 추가는 역효과
4-3.Query Ensemble

- 쿼리와 Pre-Retrieval 단계에서 검색된 문서들을 여러 모델로 임베딩하는 방식.
- 이는 다양한 값의 벡터로 임베딩되고 이를 종합하여 성능을 증가시키는 아이디어다.
- 모델별로 서로 다른 가중치 적용 가능. ➡️ Parameter Search
4-4.Reranker
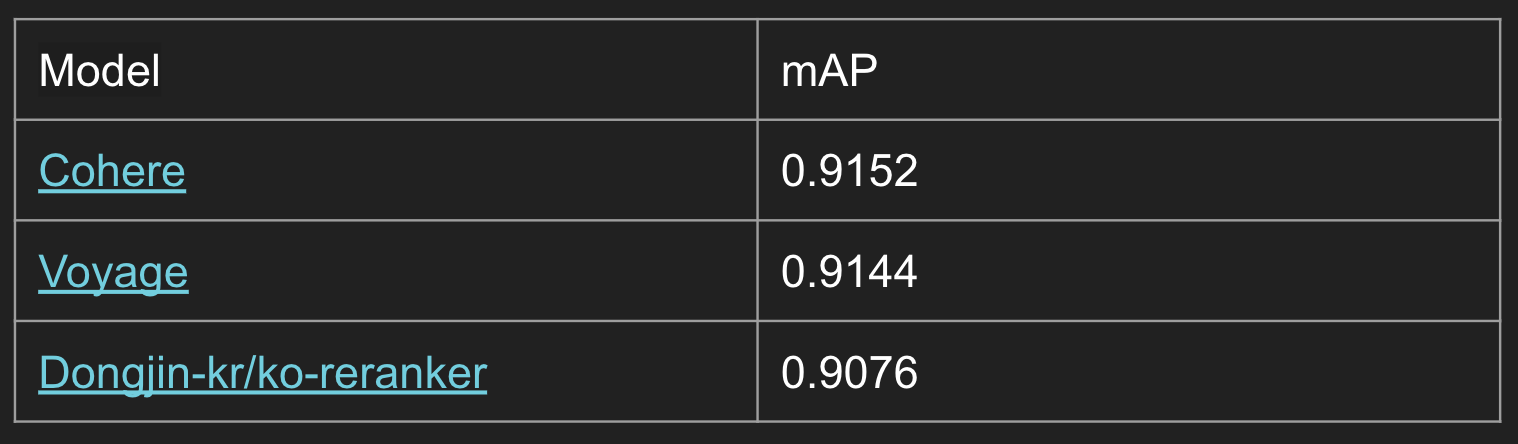
- 검색된 문서들의 순위를 재조정하는 방법.
- pre-retrieval 단계에서 10개의 문서들을 추출하고, reranker에 전달.
- reranker는 top3를 선택해 반환.
- 몇가지 Reranker 모델들을 활용해봤지만 점수는 향상되지 않았다.
5.고려사항.
지금까지 살펴본 방법들은 성능개선은 분명했으나 단점도 존재한다.
- Parameter Search로 적절한 weight, 모델들의 조합을 탐색하는 시간 필요.
- Query Ensemble은 GPU 사용량이 증가하며, 앙상블 모델별로 전체 문서에 대한 임베딩을 미리 구해야하므로 실행시간 증가한다.
- Contextual Retriever는 문서와 파생된 각각의 청크를 LLM에 입력하는 방식.
- 처리해야할 데이터양 자체가 많기 때문에 시간, 비용 소모가 크다.
- 성능이 좋은 LLM일수록 퀄리티가 좋지만 그만큼 비싸다.
- Anthropic의 Claude는 prompt cachin 기능으로 문서를 캐싱하여 청크에 대한 비용만 지불.
- 그러나 RPM(Requests Per Minutes) 제한에 의해 강제로 대기 시간을 부여하므로 시간 소모가 더 크다.
6.Reference
- Langchain https://python.langchain.com/docs/versions/v0_3/
- Contextual Retrieval, Ensemble Retriever https://www.anthropic.com/news/contextual-retrieval
- Query Ensemble https://www.kaggle.com/competitions/kaggle-llm-science-exam/discussion/446358
- Convex Combination
댓글남기기